A gente criou um app que descobre onde suas fotos antigas foram tiradas
Criamos um app desktop que manda suas fotos pra modelos de IA com visão, recebe dados de localização de volta e grava coordenadas GPS direto nos arquivos.
Todo mundo tem aquela pasta. Centenas de fotos de viagens antigas, backups de celular, downloads aleatórios. Todas com nomes tipo IMG_4523.jpg ou DSC_0091.CR2. Sem dados de GPS, sem localização, nada útil nos metadados. Você lembra vagamente que uma foto era de Praga, mas qual? Sem ideia.
Google Photos tenta resolver isso, mas você precisa subir tudo pros servidores do Google. Apple Photos faz algo parecido se você estiver no ecossistema deles. Os dois mantêm os dados presos nas suas plataformas. A gente queria algo diferente: um app que olha suas fotos, descobre onde foram tiradas e grava essa informação de volta nos próprios arquivos. Quando você termina, as coordenadas GPS estão nos dados EXIF, os arquivos têm nomes úteis e você não precisa de nenhum app específico pra ler eles.
Quem realmente usa isso
Pessoas sentadas em anos de fotos desorganizadas que ficam dizendo “um dia eu organizo isso.” Fotógrafos que fotografam em RAW e não têm GPS no corpo da câmera. Corretores de imóveis com fotos de propriedades que precisam de dados de localização. Vendedores do eBay que fotografam produtos no local e querem o GPS gravado no arquivo. Qualquer pessoa que já abriu uma pasta de fotos e pensou “onde foi isso?”
Também, pessoas que não querem subir toda a biblioteca de fotos pra um serviço na nuvem só pra ter tags de localização. As fotos são enviadas pra um provedor de IA pra análise (Google, OpenAI ou Anthropic), mas não ficam armazenadas em lugar nenhum. Seus arquivos ficam na sua máquina. Os resultados ficam num banco de dados local.
A stack técnica
O app é Electron com React e TypeScript no frontend, estilizado com Tailwind CSS v4. Os dados ficam num banco SQLite local via better-sqlite3. A gente usa exiftool-vendored pra gravar GPS e outros metadados nos arquivos de imagem, e exifr pra ler qualquer dado EXIF que já exista. As chamadas de IA passam pelos SDKs oficiais do Google Gemini, OpenAI e Anthropic. O sistema de build é electron-vite pro desenvolvimento e electron-builder pra empacotar instaladores.
Nada exótico. A gente escolheu ferramentas chatas e bem mantidas de propósito. Electron recebe críticas pelo uso de memória, mas pra uma ferramenta desktop de fotos que as pessoas rodam de vez em quando, tá de boa. Isso permitiu que a gente lançasse pra Windows, macOS e Linux a partir de uma única base de código, sem nenhum código específico de plataforma.
A parte mais difícil: parsing de coordenadas GPS
Nem chegou perto de qualquer outra coisa.
O problema é o seguinte: você pergunta pra três modelos de IA diferentes “onde essa foto foi tirada?” e recebe três formatos de resposta completamente diferentes. Gemini pode te dar {lat: 33.49, lng: -111.93}. OpenAI pode aninhar sob {gps_coordinates: {latitude: "33.49 N"}}. Alguns modelos retornam uma string separada por vírgula tipo "33.49, -111.93". Outros usam formato DMS tipo "33°29'N". Alguns envolvem tudo num array sem motivo nenhum.
A gente acabou escrevendo um normalizador que tenta campos diretos primeiro (lat, latitude, lat_degrees), depois verifica objetos aninhados sob quatro nomes de chave diferentes, depois tenta fazer parsing de strings separadas por vírgula, e depois lida com notação DMS. São umas 50 linhas de código defensivo que existem puramente porque modelos de IA não conseguem concordar num formato de resposta. Mesmo quando você diz exatamente o que quer.
O melhor bug foi o problema do zero falsy. A gente tinha Number(val) || null pra converter valores. Funciona muito bem, exceto quando a latitude é 0 (que é o equador). Number(0) é 0, que é falsy em JavaScript. Então 0 || null te dá null. A gente estava silenciosamente descartando toda coordenada GPS no equador. Demorou mais do que a gente gostaria de admitir pra encontrar.
// Before (broken):
const lat = Number(val) || null // 0 becomes null
// After:
function toNum(v: unknown): number | null {
const n = Number(v)
return isNaN(n) ? null : n
}A gente não percebeu por um bom tempo porque nenhuma das nossas fotos de teste era do equador. Encontramos quando adicionamos um caso de teste pra valores extremos e 0 voltou como null.
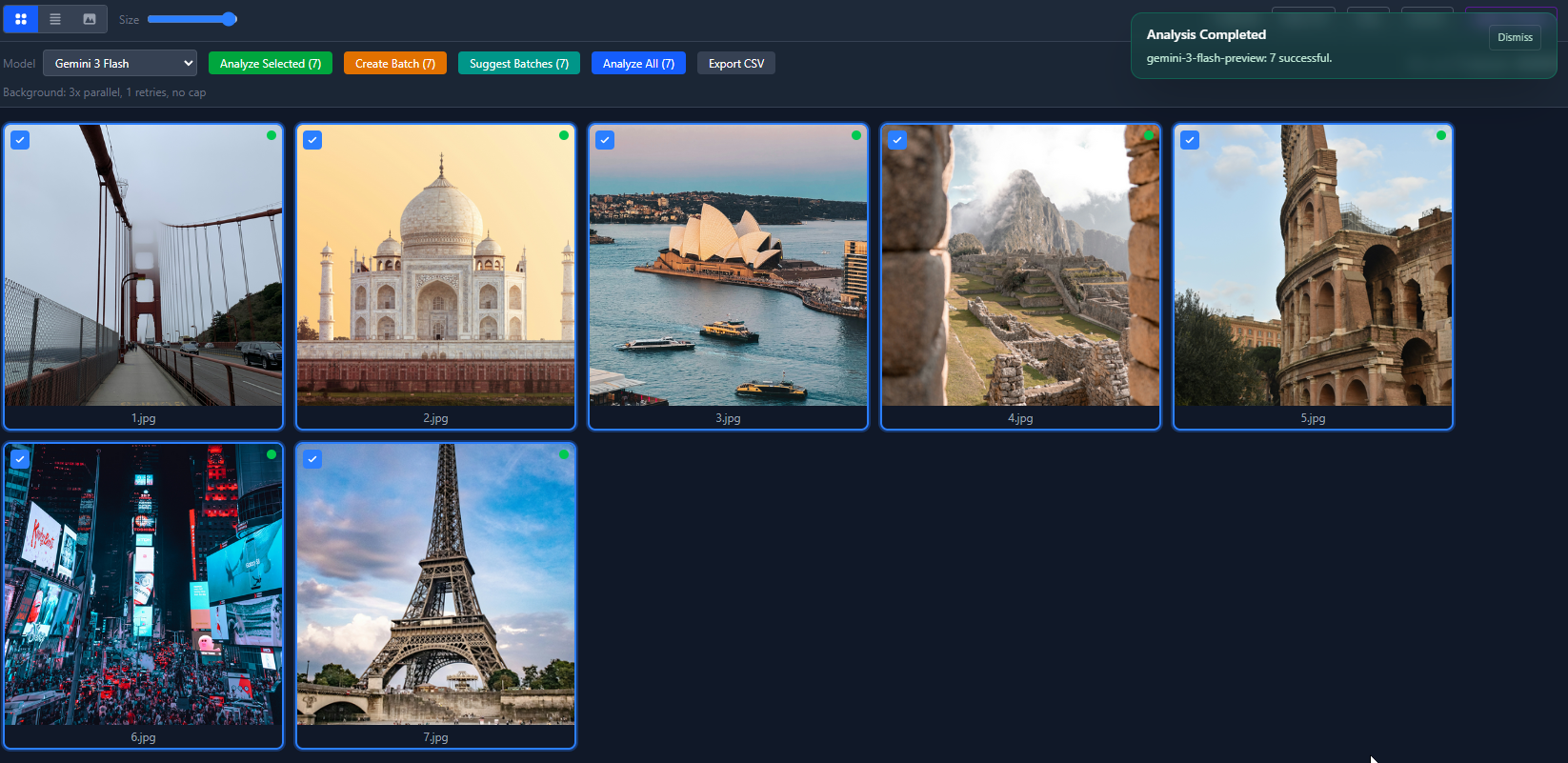
Aqui está como 7 fotos analisadas aparecem na visualização em grade. Pontos verdes significam que a IA identificou a localização. Pontos vermelhos significam baixa confiança.
Como os dados fluem
A arquitetura é direta:
- O usuário abre uma pasta. A gente escaneia ela em busca de arquivos de imagem e cria um “batch” no SQLite, com uma linha por imagem.
- O usuário clica em Analyze. Pra cada imagem, a gente lê o arquivo, codifica em base64 e manda pro provedor de IA que ele escolheu. O prompt pede localização, cidade, estado, país, coordenadas GPS, estimativa de data e um nível de confiança.
- A resposta da IA volta como JSON (geralmente). A gente passa ela pelo nosso normalizador pra lidar com todas as variações de formato, valida contra um schema Zod e armazena o resultado no banco de dados. Se o modelo retorna lixo, o Zod pega e a tarefa é marcada como falha.
- O usuário revisa os resultados. Ele pode aprovar, rejeitar ou editar cada um. O app mostra os dados EXIF originais ao lado dos resultados da IA pra que ele possa comparar.
- O usuário clica em Apply Changes. A gente copia cada arquivo original pra uma pasta de saída, usa exiftool-vendored pra gravar coordenadas GPS na cópia e renomeia ela com base num template. Os originais nunca são modificados.
A análise roda através de um sistema de fila que lida com concorrência (múltiplas imagens analisadas ao mesmo tempo), tentativas em caso de falha, pausa/retomada e limites de custo. Tudo é rastreado no SQLite. Se o app travar no meio de um batch, ele retoma de onde parou.
O modelo de processos do Electron adiciona alguma complexidade. As chamadas de IA e I/O de arquivo acontecem no processo principal. A UI roda no processo renderer. A comunicação entre eles passa por handlers IPC. A gente tem uns 40 endpoints IPC. É bastante, mas cada um faz uma coisa só.
O que ele realmente consegue fazer
Análise de IA com múltiplos provedores
O app funciona com 16+ modelos entre Google Gemini, OpenAI e Anthropic. Cada provedor tem sua própria integração via SDK com suporte a saída estruturada (Gemini usa responseSchema, OpenAI usa zodResponseFormat, Anthropic usa output_format). Quando uma resposta chega, ela passa por um normalizador que mapeia qualquer nome de campo que o modelo usou (location_name, locationName, specific_location, place) pro nosso formato padrão. O resto do app nunca sabe qual modelo produziu o resultado.
Aqui está a visualização em lista depois de rodar todas as 7 fotos pelo Gemini 3 Flash. Todas voltaram com alta confiança. Custo total abaixo de um centavo.
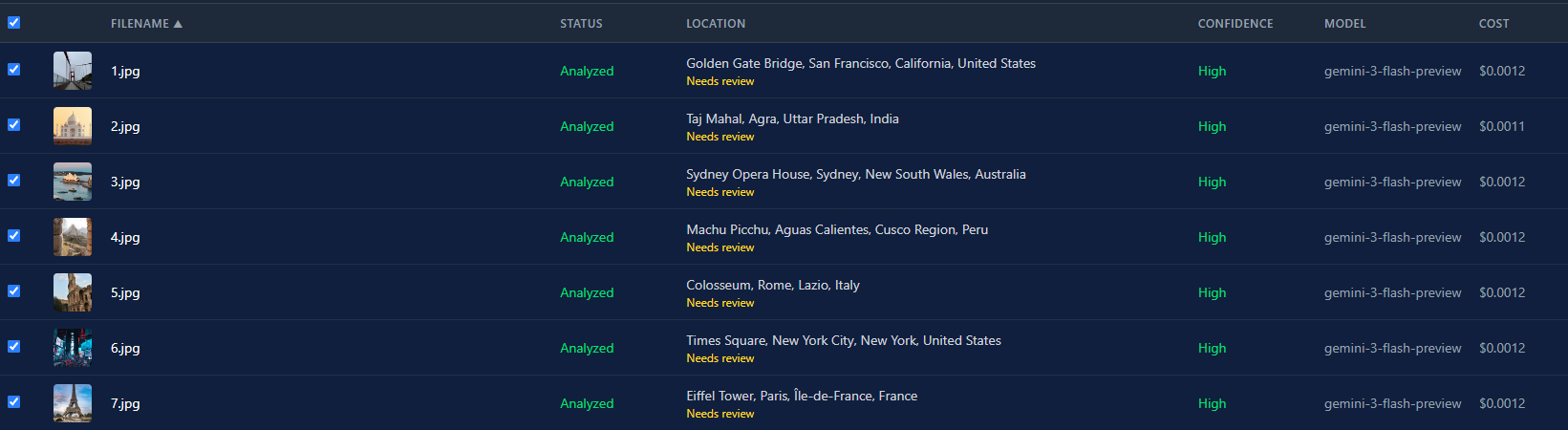
A diferença de custo entre modelos é enorme. Gemini 3 Flash custa cerca de $0.0004 por imagem. GPT-5 fica em torno de $0.02. Isso é uma diferença de 50x. Pra um batch de 500 fotos, são $0.20 vs. $10. O seletor de modelo não é só questão de preferência. É uma decisão real de orçamento.
Gravação de GPS pra praticamente todo formato de imagem
A gente começou com piexifjs pra gravar dados EXIF, mas ele só lida com JPEG. Isso era ok até a gente testar com bibliotecas de fotos reais. As pessoas têm PNGs de screenshots, HEICs de iPhones, TIFFs de scanners e arquivos RAW de câmeras. Então a gente trocou pra exiftool-vendored, que é um wrapper do ExifTool do Phil Harvey. Ele grava GPS em JPEG, PNG, TIFF, WebP, HEIC, HEIF, AVIF e vários formatos RAW (DNG, CR2, CR3, NEF, ARW, ORF, RW2).
O app sempre grava numa cópia, nunca no original. Ele cria uma pasta de saída, copia cada arquivo pra lá e grava dados GPS na cópia. Se você também tiver renomeação ativada, a cópia recebe o novo nome. Um arquivo de saída por imagem com tudo aplicado.
Classificação de erros que economiza tempo
Quando uma chamada de API falha, a gente olha o erro e separa em um de quatro baldes: auth (chave de API inválida ou expirada), rate-limit (muitas requisições), network (conexão falhou, timeout, problemas de DNS) ou unknown. Isso importa porque erros de auth nunca devem ser retentados. Se sua chave de API está errada, retentar 3 vezes só desperdiça 30 segundos. Erros de rate-limit e network são retentados porque geralmente são temporários.
export function classifyApiError(error: unknown): ErrorCategory {
const msg = (error instanceof Error ? error.message : String(error))
.toLowerCase()
const status = (error as { status?: number })?.status ??
(error as { statusCode?: number })?.statusCode
if (status === 401 || status === 403 ||
msg.includes('api key') || msg.includes('unauthorized')) {
return 'auth'
}
if (status === 429 || msg.includes('rate limit') ||
msg.includes('quota')) {
return 'rate-limit'
}
if (msg.includes('econnrefused') || msg.includes('fetch failed') ||
msg.includes('etimedout') || msg.includes('socket hang up')) {
return 'network'
}
return 'unknown'
}
// In the queue, the classification controls retry behavior:
const shouldRetry =
category !== 'auth' &&
!currentRun.cancelRequested &&
!this.isRunCostExceeded(run) &&
task.attemptCount <= run.retryLimitÉ pattern matching, não ciência. Mas pega os casos comuns e previne o modo de falha mais frustrante: ficar assistindo o app retentar uma chave de API errada várias vezes.
Processamento em batch que não perde seu trabalho
Você pode jogar 500 fotos no app e ir embora. Ele processa elas com múltiplos workers concorrentes (configurável, padrão 3), rastreia o progresso no SQLite e reporta custo em tempo real usando contagens reais de tokens das respostas da API. Não são estimativas. Se você definir um limite de custo de $2.00, o app para de analisar quando atinge esse limite e marca as imagens restantes como puladas.
O sistema de fila é à prova de crash. Toda mudança de estado de tarefa vai pro banco de dados antes de qualquer outra coisa acontecer. Se o Electron travar, a energia acabar ou você forçar o fechamento do app, o próximo lançamento detecta execuções interrompidas e retoma de onde pararam. Você não vai perder 200 análises concluídas porque o app travou na imagem 201.
Você também pode pausar no meio de um batch. Útil se você percebeu que escolheu o modelo errado ou quer verificar resultados iniciais antes de continuar. E se a primeira passada voltar com baixa confiança em algumas imagens, você pode configurar auto-upgrade: o app roda só aquelas imagens de novo com um modelo mais caro.
Comparação lado a lado de EXIF
A visualização detalhada puxa dados EXIF originais do arquivo usando exifr (modelo da câmera, data da foto, dimensões e qualquer GPS existente) e mostra ao lado dos resultados da análise de IA. Isso é útil de duas formas. Primeiro, se a foto já tinha GPS gravado, você pode ver se a IA concorda. Se as coordenadas estão muito diferentes, é um sinal de alerta. Segundo, o modelo da câmera e a data ajudam a verificar a estimativa de data da IA. Se o EXIF diz “Canon EOS R5, March 2023” e a IA diz “estimated 2015-2018”, algo está errado.
Decisões que a gente tomou
A maior: BYOK (bring your own API key). Os usuários precisam ir ao Google AI Studio ou ao dashboard da OpenAI, criar uma chave de API e colar nas configurações. Isso é atrito real. Usuários não técnicos não vão fazer.
Mas a alternativa era rodar nosso próprio proxy de API. Isso significa construir um backend, configurar cobrança, lidar com medição de uso, tratar abuso e pagar por servidores. Pra um projeto paralelo que a gente não tinha certeza se alguém iria usar, é muita infraestrutura. BYOK significa que o app é completamente standalone. A gente distribui um binário, os usuários rodam, a gente não mantém nada.
A gente também decidiu contra modelos de IA locais. Gemma 4, LLaVA e modelos similares conseguem fazer entendimento básico de imagem. Mas quando a gente testou eles pra identificação de localização, os resultados eram vagos. “Isso parece uma praia” não ajuda quando você precisa de “Praia de Copacabana, Rio de Janeiro, Brasil.” Modelos na nuvem são genuinamente melhores nisso porque viram mais da internet. Os requisitos de hardware pra rodar um modelo de visão decente localmente excluiriam a maioria das pessoas que realmente iam querer esse app.
A terceira decisão foi suportar três provedores de IA desde o primeiro dia em vez de só um. Isso triplicou o trabalho de integração de API. Honestamente, 90% dos usuários vão usar Gemini porque é o mais barato. Mas ter opções importa se você já tem uma chave da OpenAI e não quer se cadastrar em outro serviço.
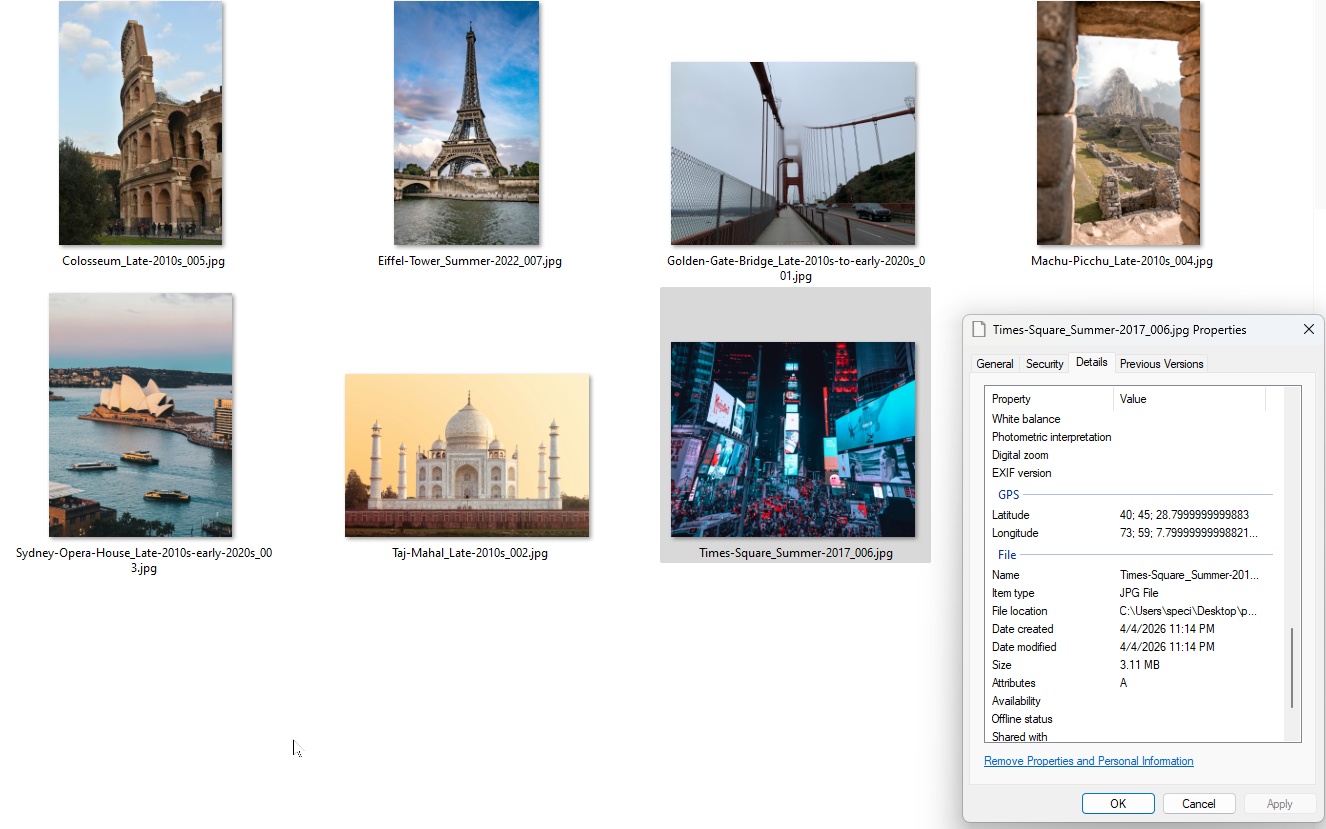
E aqui está a saída. Arquivos renomeados com coordenadas GPS gravadas nos dados EXIF. Você pode verificar nas propriedades do arquivo no Windows.
O que a gente faria diferente
A gente lançaria só com Gemini e adicionaria outros provedores baseado na demanda. Três integrações foi três vezes o trabalho, três vezes os casos extremos, três vezes os testes.
A gente também gastaria menos tempo indo e voltando em precificação. Debatemos grátis vs. pago vs. freemium vs. open source por tempo demais. Esse tempo teria sido melhor gasto no produto em si. No final, fomos de open source. Levou uns 30 segundos pra essa decisão se firmar quando a gente parou de pensar demais.
No lado técnico, a gente pensaria mais no schema do banco de dados logo de cara. A gente adicionou colunas e migrações várias vezes conforme novas funcionalidades chegavam (como o campo de estado pra localizações, que a gente não tinha inicialmente). Começar com um schema um pouco mais flexível teria economizado algumas rodadas de ALTER TABLE.