On a créé un truc qui devine où tes vieilles photos ont été prises
On a créé une appli desktop qui envoie tes photos à des modèles d'IA, récupère les données de localisation, et écrit les coordonnées GPS directement dans les fichiers.
Tout le monde a ce dossier. Des centaines de photos de vieux voyages, de sauvegardes de téléphone, de téléchargements au hasard. Elles s’appellent toutes IMG_4523.jpg ou DSC_0091.CR2. Pas de GPS, pas de localisation, rien de pertinent dans les métadonnées. Tu te souviens vaguement qu’une photo venait de Prague. Mais laquelle ? Aucune idée.
Google Photos essaie de résoudre ça, mais tu dois tout envoyer sur les serveurs de Google. Apple Photos fait pareil si tu es dans leur écosystème. Les deux gardent les données enfermées dans leur plateforme. On voulait autre chose. Une appli qui regarde tes photos, trouve où elles ont été prises, et écrit cette info directement dans les fichiers. Quand c’est fini, les coordonnées GPS sont dans les données EXIF, les fichiers ont des noms corrects, et tu n’as besoin d’aucune appli en particulier pour les lire.
Qui s’en sert vraiment
Des gens assis sur des années de photos pas triées qui répètent “je m’en occuperai un jour.” Des photographes qui shootent en RAW sans GPS sur leur boîtier. Des agents immobiliers avec des photos de propriétés qui ont besoin de données de localisation. Des vendeurs eBay qui photographient des produits sur place et veulent le GPS intégré. Tous ceux qui ont déjà ouvert un dossier de photos en se demandant “c’était où ça ?”
Et aussi les gens qui ne veulent pas envoyer toute leur photothèque sur un service cloud juste pour avoir des tags de localisation. Les photos sont envoyées à un fournisseur d’IA pour analyse (Google, OpenAI, ou Anthropic), mais elles ne sont stockées nulle part. Tes fichiers restent sur ta machine. Les résultats restent dans une base de données locale.
La stack technique
L’appli tourne sur Electron avec React et TypeScript côté frontend, stylé avec Tailwind CSS v4. Les données vivent dans une base SQLite locale via better-sqlite3. On se sert de exiftool-vendored pour écrire les GPS et autres métadonnées dans les fichiers image. Et exifr pour lire les données EXIF déjà présentes. Les appels IA passent par les SDK officiels de Google Gemini, OpenAI, et Anthropic. Le build repose sur electron-vite pour le développement et electron-builder pour les installeurs.
Rien d’exotique. On a choisi des outils simples et bien maintenus, volontairement. Electron se fait critiquer pour la mémoire, mais pour un outil photo desktop qu’on lance de temps en temps, ça va. Ça nous a permis de livrer pour Windows, macOS, et Linux à partir d’une seule codebase sans code spécifique à une plateforme.
La partie la plus difficile : le parsing des coordonnées GPS
De loin la pire.
Le problème : tu demandes à trois modèles d’IA différents “où est-ce que cette photo a été prise ?” et tu reçois trois formats de réponse complètement différents. Gemini peut te donner {lat: 33.49, lng: -111.93}. OpenAI peut l’imbriquer sous {gps_coordinates: {latitude: "33.49 N"}}. Certains modèles renvoient une chaîne séparée par des virgules comme "33.49, -111.93". D’autres le format DMS comme "33°29'N". Quelques-uns mettent tout dans un tableau sans raison.
On a fini par écrire un normaliseur qui essaie d’abord les champs directs (lat, latitude, lat_degrees), puis vérifie les objets imbriqués sous quatre noms de clés différents, puis tente de parser des chaînes séparées par des virgules, puis gère la notation DMS. C’est environ 50 lignes de code défensif qui existent uniquement parce que les modèles d’IA ne se mettent pas d’accord sur un format de réponse. Même quand tu leur dis exactement ce que tu veux.
Le meilleur bug, c’était le problème du zéro falsy. On avait Number(val) || null pour convertir les valeurs. Ça marche très bien, sauf quand la latitude est 0 (c’est-à-dire l’équateur). Number(0) donne 0, qui est falsy en JavaScript, donc 0 || null donne null. On supprimait silencieusement toutes les coordonnées GPS sur l’équateur. Ça nous a pris plus de temps à trouver qu’on voudrait l’admettre.
// Before (broken):
const lat = Number(val) || null // 0 becomes null
// After:
function toNum(v: unknown): number | null {
const n = Number(v)
return isNaN(n) ? null : n
}On ne l’a pas remarqué pendant un moment parce qu’aucune de nos photos de test ne venait de l’équateur. On l’a trouvé en ajoutant un cas de test pour les valeurs limites. Le 0 revenait null.
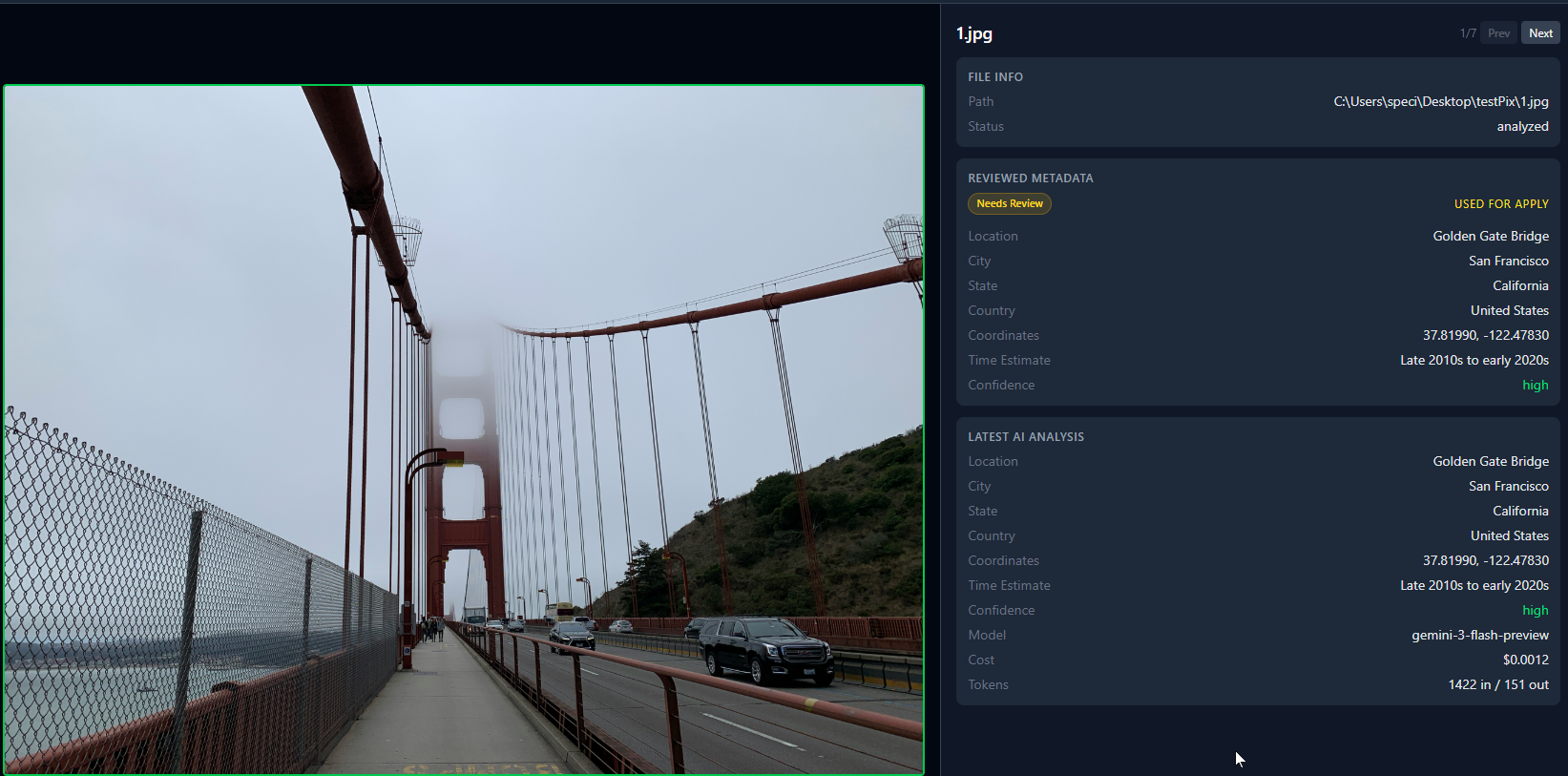
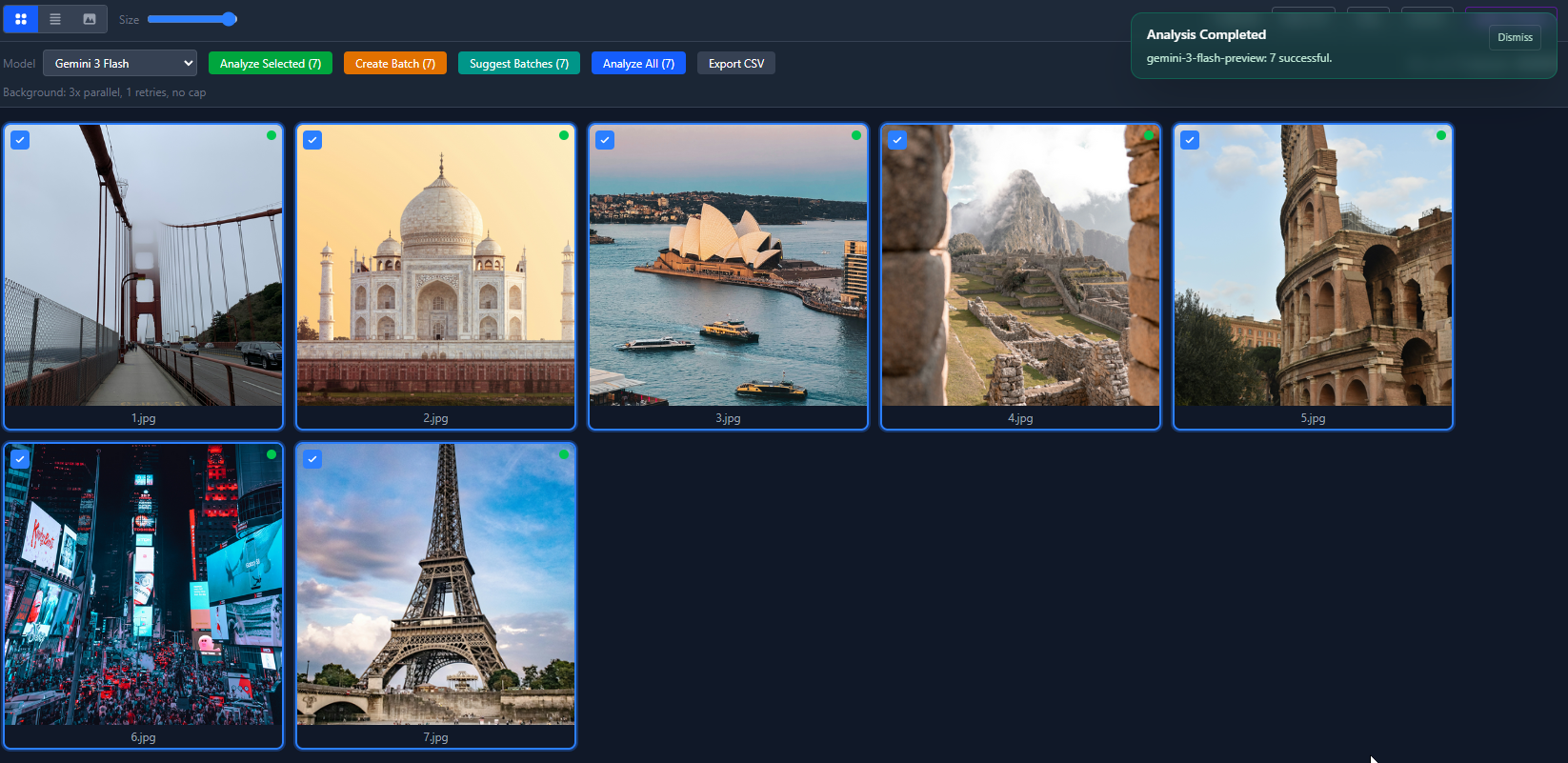
Voici à quoi ressemblent 7 photos analysées dans la vue en grille. Les points verts signifient que l’IA a identifié la localisation. Les points rouges signifient une confiance faible.
Comment les données circulent
L’architecture est simple :
- L’utilisateur ouvre un dossier. On le scanne pour trouver les fichiers image et on crée un “batch” dans SQLite, avec une ligne par image.
- L’utilisateur clique sur Analyser. Pour chaque image, on lit le fichier, on l’encode en base64, et on l’envoie au fournisseur d’IA choisi. Le prompt demande la localisation, la ville, l’état, le pays, les coordonnées GPS, une estimation de date, et un niveau de confiance.
- La réponse de l’IA revient en JSON (en général). On la passe dans notre normaliseur pour gérer toutes les variations de format, on la valide avec un schéma Zod, et on stocke le résultat dans la base de données. Si le modèle renvoie n’importe quoi, Zod le détecte et la tâche est marquée comme échouée.
- L’utilisateur passe en revue les résultats. Il peut approuver, rejeter, ou modifier chacun. L’appli montre les données EXIF d’origine à côté des résultats de l’IA pour comparer.
- L’utilisateur clique sur Appliquer les changements. On copie chaque fichier original dans un dossier de sortie, on écrit les coordonnées GPS dans la copie avec exiftool-vendored, et on renomme selon un modèle. Les originaux ne sont jamais modifiés.
L’analyse passe par un système de file d’attente qui gère la concurrence (plusieurs images analysées en même temps), les réessais en cas d’échec, la pause/reprise, et les plafonds de coût. Tout est suivi dans SQLite. Si l’appli plante en plein batch, elle reprend là où elle s’est arrêtée.
Le modèle de processus d’Electron ajoute un peu de complexité. Les appels IA et les opérations fichier se font dans le processus principal. L’UI tourne dans le processus renderer. La communication entre les deux passe par des handlers IPC. On a environ 40 endpoints IPC. C’est beaucoup, mais chacun fait une seule chose.
Ce que l’appli sait vraiment faire
Analyse IA multi-fournisseurs
L’appli fonctionne avec 16+ modèles chez Google Gemini, OpenAI, et Anthropic. Chaque fournisseur a sa propre intégration SDK avec support de sortie structurée (Gemini avec responseSchema, OpenAI avec zodResponseFormat, Anthropic avec output_format). Quand une réponse arrive, elle passe par un normaliseur qui fait correspondre les noms de champs du modèle (location_name, locationName, specific_location, place) à notre format standard. Le reste de l’appli ne sait jamais quel modèle a produit le résultat.
Voici la vue en liste après avoir passé les 7 photos dans Gemini 3 Flash. Toutes sont revenues avec une confiance élevée. Le coût total est inférieur à un centime.
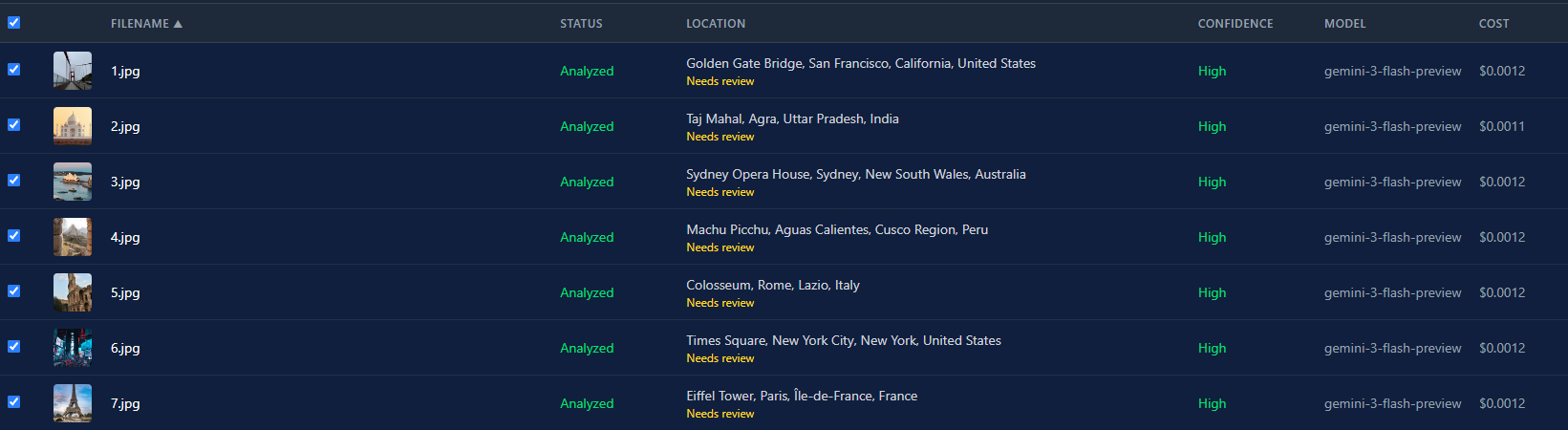
La différence de coût entre les modèles est énorme. Gemini 3 Flash coûte environ $0.0004 par image. GPT-5 tourne autour de $0.02. C’est un facteur 50. Pour un batch de 500 photos, ça fait $0.20 contre $10. Le choix du modèle n’est pas juste une préférence. C’est une vraie décision de budget.
Écriture GPS pour à peu près tous les formats d’image
On a commencé avec piexifjs pour écrire les données EXIF, mais il ne gère que le JPEG. C’était suffisant jusqu’à ce qu’on teste avec de vraies photothèques. Les gens ont des PNG de captures d’écran, des HEIC d’iPhone, des TIFF de scanners, et des fichiers RAW d’appareils photo. On est passés à exiftool-vendored, qui encapsule l’ExifTool de Phil Harvey. Il écrit le GPS en JPEG, PNG, TIFF, WebP, HEIC, HEIF, AVIF, et pas mal de formats RAW (DNG, CR2, CR3, NEF, ARW, ORF, RW2).
L’appli écrit toujours dans une copie, jamais dans l’original. Elle crée un dossier de sortie, copie chaque fichier dedans, puis écrit les données GPS dans la copie. Si le renommage est aussi activé, la copie prend le nouveau nom. Un seul fichier de sortie par image avec tout appliqué.
Classification d’erreurs qui fait gagner du temps
Quand un appel API échoue, on regarde l’erreur et on la trie dans un de quatre groupes : auth (clé API mauvaise ou expirée), rate-limit (trop de requêtes), réseau (connexion échouée, timeout, problèmes DNS), ou inconnu. C’est important parce que les erreurs d’auth ne devraient jamais être réessayées. Si ta clé API est fausse, réessayer 3 fois fait juste perdre 30 secondes. Les erreurs de rate-limit et de réseau sont réessayées parce qu’elles sont en général temporaires.
export function classifyApiError(error: unknown): ErrorCategory {
const msg = (error instanceof Error ? error.message : String(error))
.toLowerCase()
const status = (error as { status?: number })?.status ??
(error as { statusCode?: number })?.statusCode
if (status === 401 || status === 403 ||
msg.includes('api key') || msg.includes('unauthorized')) {
return 'auth'
}
if (status === 429 || msg.includes('rate limit') ||
msg.includes('quota')) {
return 'rate-limit'
}
if (msg.includes('econnrefused') || msg.includes('fetch failed') ||
msg.includes('etimedout') || msg.includes('socket hang up')) {
return 'network'
}
return 'unknown'
}
// In the queue, the classification controls retry behavior:
const shouldRetry =
category !== 'auth' &&
!currentRun.cancelRequested &&
!this.isRunCostExceeded(run) &&
task.attemptCount <= run.retryLimitC’est du pattern matching, pas de la science. Mais ça attrape les cas courants et empêche le mode d’échec le plus frustrant : regarder l’appli réessayer une mauvaise clé API encore et encore.
Traitement par batch qui ne perd pas ton travail
Tu peux lancer 500 photos dans l’appli et partir faire autre chose. Elle les traite avec plusieurs workers en parallèle (configurable, 3 par défaut), suit la progression dans SQLite, et rapporte le coût en temps réel avec les vrais nombres de tokens des réponses API. Pas des estimations. Si tu mets un plafond de coût à $2.00, l’appli arrête l’analyse une fois la limite atteinte et marque les images restantes comme ignorées.
Le système de file d’attente résiste aux crashs. Chaque changement d’état de tâche est écrit en base de données avant tout le reste. Si Electron plante, si le courant saute, ou si tu force-quit l’appli, le prochain lancement détecte les exécutions interrompues et reprend là où elles se sont arrêtées. Tu ne perdras pas 200 analyses terminées parce que l’appli a planté sur l’image 201.
Tu peux aussi mettre en pause en plein batch. Pratique si tu te rends compte que tu as choisi le mauvais modèle ou si tu veux vérifier les premiers résultats avant de continuer. Et si le premier passage donne une confiance faible sur certaines images, tu peux configurer l’upgrade automatique : l’appli relance juste ces images avec un modèle plus cher.
Comparaison EXIF côte à côte
La vue détaillée récupère les données EXIF d’origine du fichier avec exifr (modèle d’appareil photo, date de prise de vue, dimensions, et tout GPS déjà existant) et les affiche à côté des résultats de l’IA. C’est pratique pour deux raisons. D’abord, si la photo avait déjà du GPS intégré, tu peux voir si l’IA est d’accord. Si les coordonnées sont très différentes, c’est un signal d’alerte. Ensuite, le modèle d’appareil et la date t’aident à vérifier l’estimation temporelle de l’IA. Si l’EXIF dit “Canon EOS R5, mars 2023” et que l’IA dit “estimé 2015-2018”, quelque chose ne colle pas.
Les compromis qu’on a faits
Le plus gros : BYOK (bring your own API key). Les utilisateurs doivent aller sur Google AI Studio ou le dashboard d’OpenAI, créer une clé API, et la coller dans nos paramètres. C’est de la vraie friction. Les utilisateurs non techniques ne le feront pas.
Mais l’alternative, c’était de faire tourner notre propre proxy API. Ça veut dire construire un backend, mettre en place la facturation, gérer le suivi de consommation, gérer les abus, et payer des serveurs. Pour un projet perso dont on ne savait pas si quelqu’un s’en servirait, c’est beaucoup d’infrastructure. Le BYOK fait que l’appli est complètement autonome. On livre un binaire, les utilisateurs le lancent, on ne maintient rien.
On a aussi décidé de ne pas intégrer de modèles d’IA locaux. Gemma 4, LLaVA, et des modèles similaires peuvent faire de la compréhension d’image basique. Mais quand on les a testés pour l’identification de lieux, les résultats étaient vagues. “Ça ressemble à une plage” n’aide pas quand tu as besoin de “Waikiki Beach, Honolulu, Hawaii.” Les modèles cloud sont vraiment meilleurs pour ça parce qu’ils ont vu plus d’internet. Et les besoins matériels pour faire tourner un modèle de vision correct en local excluraient la plupart des gens qui voudraient cette appli.
Le troisième compromis, c’était de supporter trois fournisseurs d’IA dès le premier jour au lieu d’un seul. Ça a triplé le travail d’intégration API. Honnêtement, 90% des utilisateurs vont juste prendre Gemini parce que c’est le moins cher. Mais avoir le choix compte si tu as déjà une clé OpenAI et que tu ne veux pas t’inscrire à un autre service.
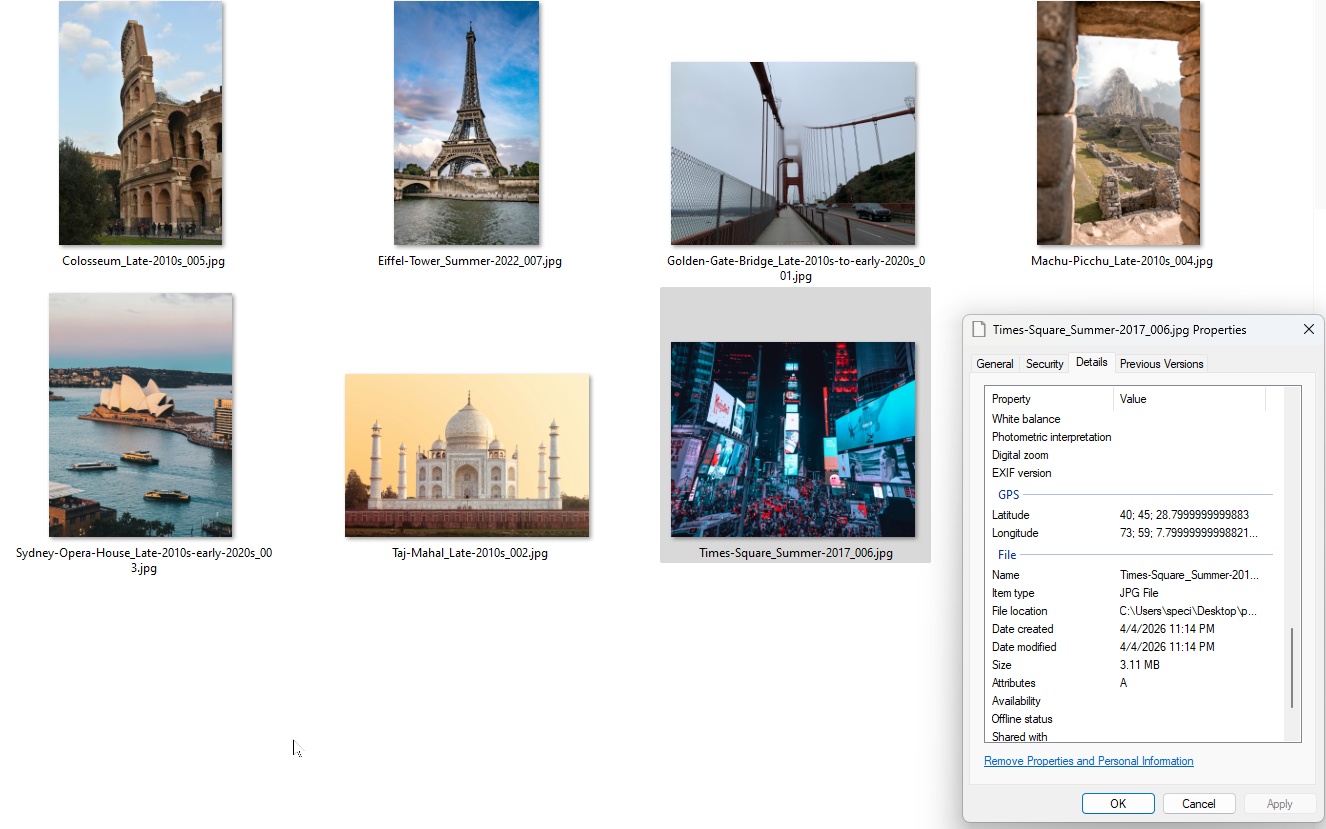
Et voici le résultat. Des fichiers renommés avec les coordonnées GPS intégrées dans les données EXIF. Tu peux le vérifier dans les propriétés du fichier sous Windows.
Ce qu’on ferait différemment
On aurait livré avec Gemini uniquement et ajouté les autres fournisseurs selon la demande. Trois intégrations, c’était trois fois le travail, trois fois les cas limites, trois fois les tests.
On aurait aussi passé moins de temps à hésiter sur le pricing. On a débattu gratuit vs. payant vs. freemium vs. open source bien trop longtemps. Ce temps aurait été mieux dépensé sur le produit lui-même. Au final, on est partis en open source. La décision a pris environ 30 secondes une fois qu’on a arrêté de trop réfléchir.
Côté technique, on aurait mieux réfléchi au schéma de base de données dès le départ. On a ajouté des colonnes et des migrations plusieurs fois au fur et à mesure des nouvelles fonctionnalités (comme le champ state pour les localisations, qu’on n’avait pas au début). Partir avec un schéma un peu plus souple nous aurait épargné quelques tours d’ALTER TABLE.