Abbiamo creato un'app che scopre dove sono state scattate le tue vecchie foto
Abbiamo costruito un'app desktop che invia le tue foto a modelli AI di visione, riceve dati sulla posizione e scrive le coordinate GPS direttamente nei file.
Tutti hanno quella cartella. Centinaia di foto da vecchi viaggi, backup del telefono, download casuali. Si chiamano tutte IMG_4523.jpg o DSC_0091.CR2. Niente dati GPS, niente posizione, niente di utile nei metadati. Ti ricordi vagamente che una foto era di Praga, ma quale? Nessuna idea.
Google Photos prova a risolvere il problema, ma devi caricare tutto sui server di Google. Apple Photos fa qualcosa di simile se sei nel loro ecosistema. Entrambi tengono i dati bloccati nelle loro piattaforme. Noi volevamo qualcosa di diverso: un’app che guarda le tue foto, capisce dove sono state scattate e scrive quell’informazione nei file stessi. Quando hai finito, le coordinate GPS sono nei dati EXIF, i file hanno nomi utili e non ti serve nessuna app particolare per leggerli.
Chi usa davvero quest’app
Persone sedute su anni di foto disorganizzate che continuano a dire “prima o poi le sistemo.” Fotografi che scattano in RAW e non hanno il GPS sul corpo macchina. Agenti immobiliari con foto di proprietà che hanno bisogno di dati di posizione. Venditori eBay che fotografano prodotti sul posto e vogliono il GPS integrato nel file. Chiunque abbia mai aperto una cartella di foto e pensato “ma dove era questa?”
Anche persone che non vogliono caricare tutta la loro libreria foto su un servizio cloud solo per avere i tag di posizione. Le foto vengono inviate a un provider AI per l’analisi (Google, OpenAI o Anthropic), ma non vengono salvate da nessuna parte. I tuoi file restano sulla tua macchina. I risultati restano in un database locale.
Lo stack tecnologico
L’app è Electron con React e TypeScript sul frontend, stilizzata con Tailwind CSS v4. I dati vivono in un database locale SQLite tramite better-sqlite3. Usiamo exiftool-vendored per scrivere GPS e altri metadati nei file immagine, ed exifr per leggere qualsiasi dato EXIF già esistente. Le chiamate AI passano attraverso gli SDK ufficiali di Google Gemini, OpenAI e Anthropic. Il sistema di build è electron-vite per lo sviluppo e electron-builder per creare gli installer.
Niente di esotico. Abbiamo scelto strumenti ben mantenuti e collaudati apposta. Electron viene criticato per l’uso di memoria, ma per un tool desktop per foto che le persone usano ogni tanto, va bene. Ci ha permesso di distribuire per Windows, macOS e Linux da un unico codebase senza codice specifico per piattaforma.
La parte più difficile: il parsing delle coordinate GPS
Non c’è stato nemmeno gara con tutto il resto.
Ecco il problema: chiedi a tre modelli AI diversi “dove è stata scattata questa foto?” e ricevi tre formati di risposta completamente diversi. Gemini potrebbe darti {lat: 33.49, lng: -111.93}. OpenAI potrebbe annidarlo sotto {gps_coordinates: {latitude: "33.49 N"}}. Alcuni modelli restituiscono una stringa separata da virgole come "33.49, -111.93". Altri usano il formato DMS come "33°29'N". Qualcuno mette tutto in un array senza motivo.
Alla fine abbiamo scritto un normalizzatore che prova prima i campi diretti (lat, latitude, lat_degrees), poi controlla oggetti annidati sotto quattro nomi di chiave diversi, poi prova a fare il parsing di stringhe separate da virgole, poi gestisce la notazione DMS. Sono circa 50 righe di codice difensivo che esistono solo perché i modelli AI non riescono a mettersi d’accordo su un formato di risposta. Anche quando gli dici esattamente cosa vuoi.
Il bug migliore è stato il problema del falsy-zero. Avevamo Number(val) || null per convertire i valori. Funziona benissimo, tranne quando la latitudine è 0 (che è l’equatore). Number(0) è 0, che è falsy in JavaScript, quindi 0 || null ti dà null. Stavamo eliminando silenziosamente ogni coordinata GPS sull’equatore. Ci abbiamo messo più tempo del previsto a trovarlo.
// Before (broken):
const lat = Number(val) || null // 0 becomes null
// After:
function toNum(v: unknown): number | null {
const n = Number(v)
return isNaN(n) ? null : n
}Non l’abbiamo notato per un po’ perché nessuna delle nostre foto di test era dall’equatore. L’abbiamo trovato quando abbiamo aggiunto un test case per valori limite e 0 tornava null.
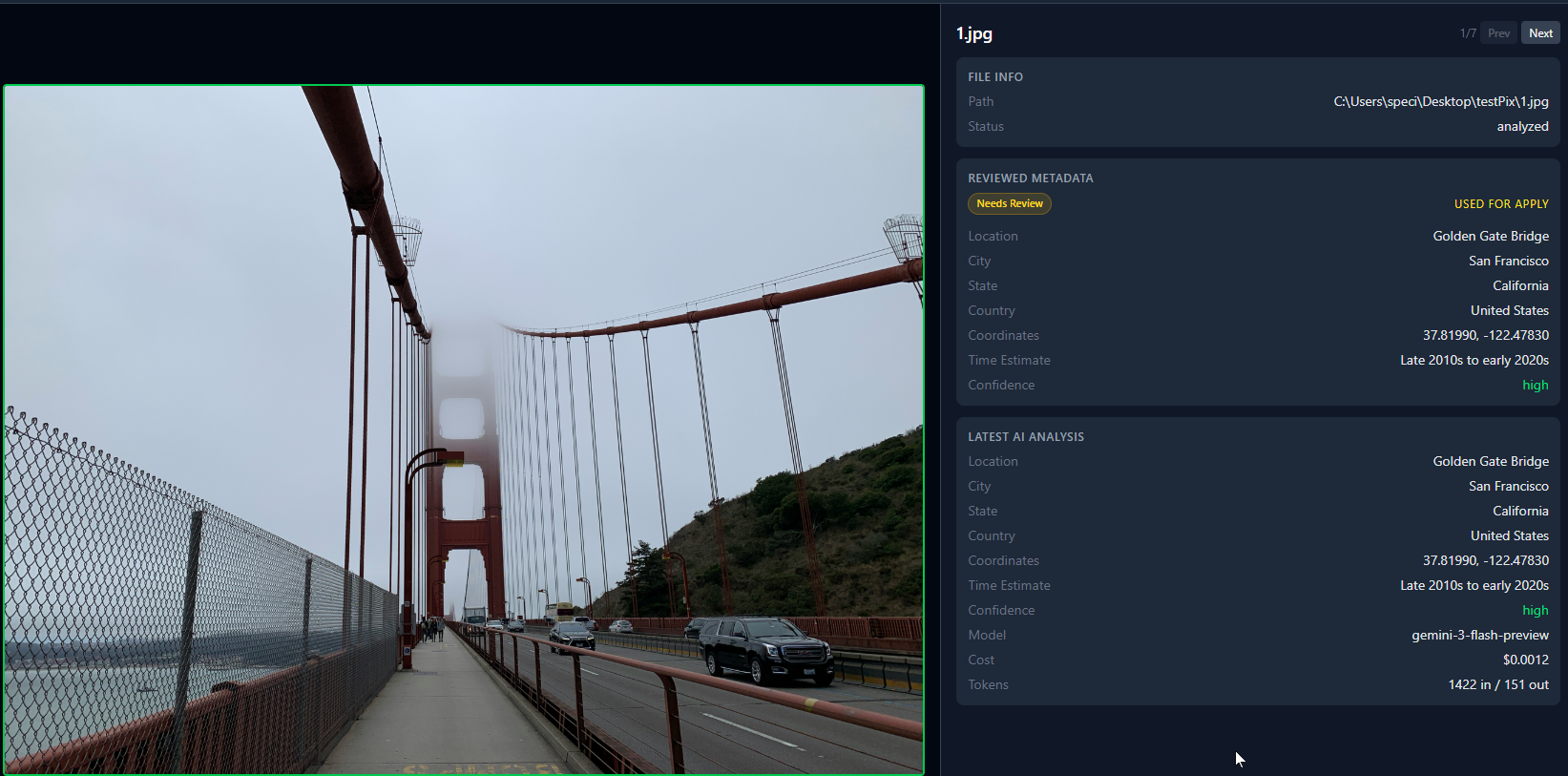
Ecco come appaiono 7 foto analizzate nella vista griglia. I pallini verdi significano che l’AI ha identificato la posizione. I pallini rossi significano bassa confidenza.
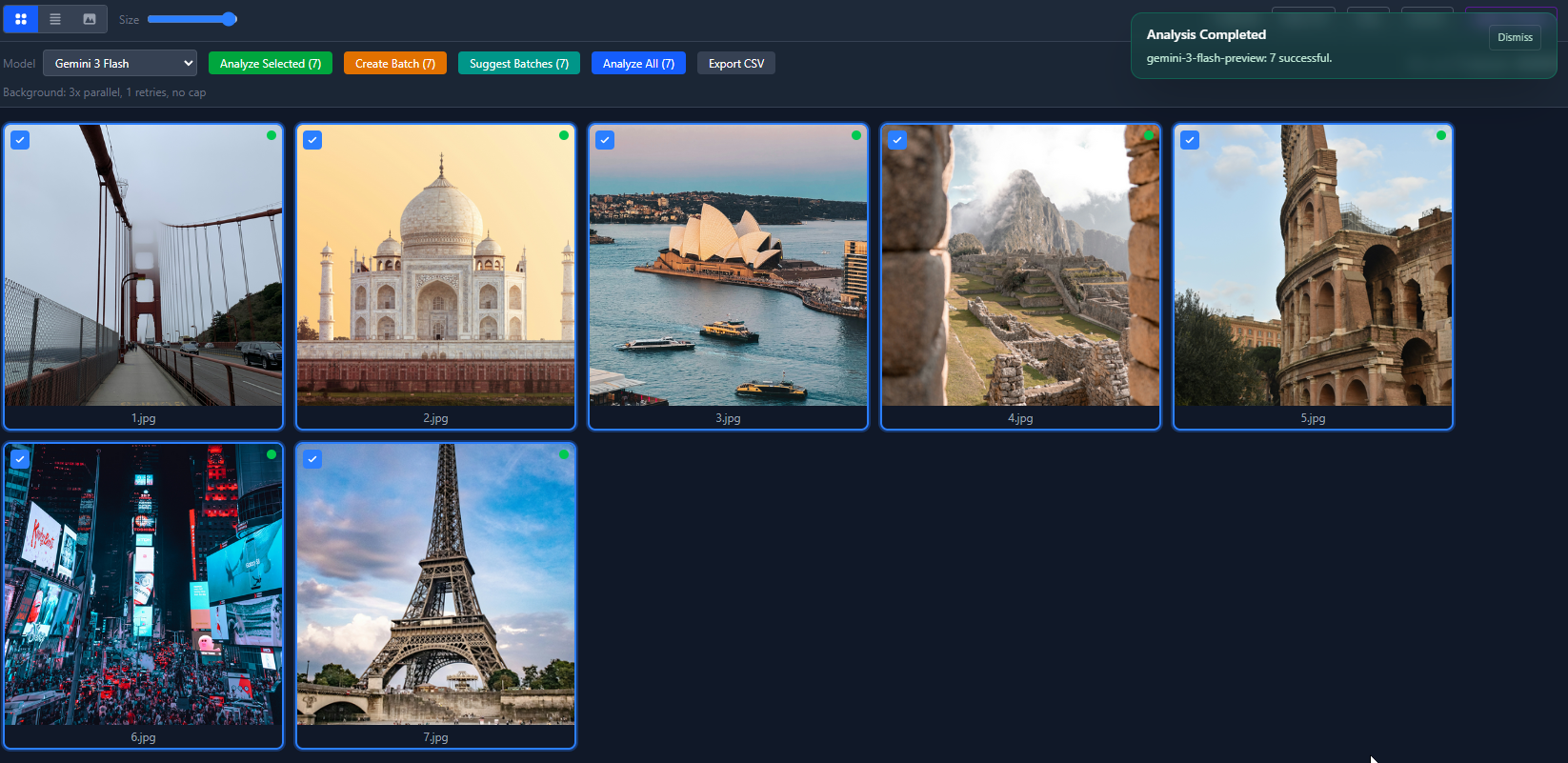
Come scorrono i dati
L’architettura è semplice:
- L’utente apre una cartella. Noi la scansioniamo cercando file immagine e creiamo un “batch” in SQLite, con una riga per immagine.
- L’utente clicca Analyze. Per ogni immagine, leggiamo il file, lo codifichiamo in base64 e lo inviamo al provider AI scelto. Il prompt chiede posizione, città, stato, paese, coordinate GPS, stima temporale e un livello di confidenza.
- La risposta AI torna come JSON (di solito). La passiamo attraverso il nostro normalizzatore per gestire tutte le variazioni di formato, la validiamo con uno schema Zod e salviamo il risultato nel database. Se il modello restituisce spazzatura, Zod lo intercetta e il task viene segnato come fallito.
- L’utente rivede i risultati. Può approvare, rifiutare o modificare ognuno. L’app mostra i dati EXIF originali accanto ai risultati AI per poter confrontare.
- L’utente clicca Apply Changes. Copiamo ogni file originale in una cartella di output, usiamo exiftool-vendored per scrivere le coordinate GPS nella copia, e lo rinominiamo in base a un template. Gli originali non vengono mai modificati.
L’analisi passa attraverso un sistema a coda che gestisce la concorrenza (più immagini analizzate contemporaneamente), i retry in caso di errore, pausa/ripresa e limiti di costo. Tutto viene tracciato in SQLite. Se l’app crasha a metà batch, riprende da dove si era fermata.
Il modello a processi di Electron aggiunge un po’ di complessità. Le chiamate AI e le operazioni su file avvengono nel processo main. La UI gira nel processo renderer. La comunicazione tra i due passa attraverso handler IPC. Abbiamo circa 40 endpoint IPC. Sono tanti, ma ognuno fa una cosa sola.
Cosa sa fare davvero
Analisi AI multi-provider
L’app funziona con 16+ modelli tra Google Gemini, OpenAI e Anthropic. Ogni provider ha la propria integrazione SDK con supporto per output strutturato (Gemini usa responseSchema, OpenAI usa zodResponseFormat, Anthropic usa output_format). Quando arriva una risposta, passa attraverso un normalizzatore che mappa qualsiasi nome di campo usato dal modello (location_name, locationName, specific_location, place) al nostro formato standard. Il resto dell’app non sa mai quale modello ha prodotto il risultato.
Ecco la vista lista dopo aver analizzato tutte e 7 le foto con Gemini 3 Flash. Tutte sono tornate con alta confidenza. Costo totale sotto un centesimo.
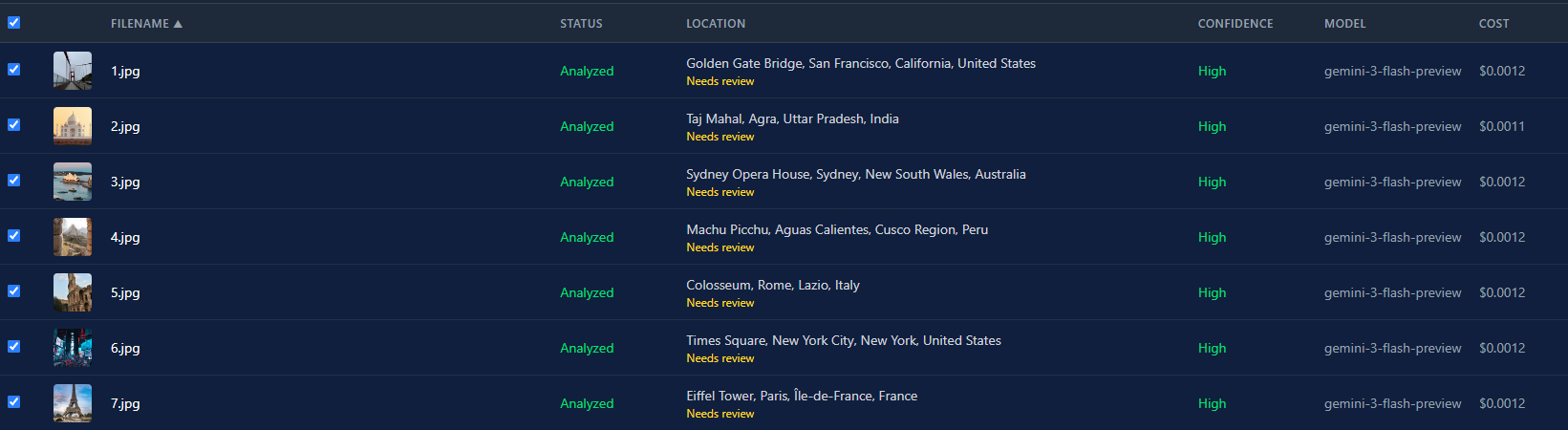
La differenza di costo tra i modelli è enorme. Gemini 3 Flash costa circa $0.0004 per immagine. GPT-5 è intorno a $0.02. Una differenza di 50 volte. Per un batch di 500 foto, significa $0.20 contro $10. Il selettore del modello non è solo una questione di preferenza. È una vera decisione di budget.
Scrittura GPS per praticamente ogni formato immagine
Abbiamo iniziato con piexifjs per scrivere i dati EXIF, ma gestisce solo JPEG. Andava bene finché non abbiamo testato con librerie foto reali. Le persone hanno PNG da screenshot, HEIC da iPhone, TIFF da scanner e file RAW da fotocamere. Quindi siamo passati a exiftool-vendored, che wrappa l’ExifTool di Phil Harvey. Scrive GPS in JPEG, PNG, TIFF, WebP, HEIC, HEIF, AVIF e un sacco di formati RAW (DNG, CR2, CR3, NEF, ARW, ORF, RW2).
L’app scrive sempre su una copia, mai sull’originale. Crea una cartella di output, copia ogni file lì, poi scrive i dati GPS nella copia. Se hai anche la rinominazione attiva, la copia prende il nuovo nome. Un file di output per immagine con tutto applicato.
Classificazione degli errori che fa risparmiare tempo
Quando una chiamata API fallisce, guardiamo l’errore e lo classifichiamo in uno di quattro gruppi: auth (chiave API sbagliata o scaduta), rate-limit (troppe richieste), network (connessione fallita, timeout, problemi DNS) o unknown. Questo conta perché gli errori auth non dovrebbero mai essere ritentati. Se la tua chiave API è sbagliata, riprovare 3 volte spreca solo 30 secondi. Gli errori rate-limit e network vengono ritentati perché di solito sono temporanei.
export function classifyApiError(error: unknown): ErrorCategory {
const msg = (error instanceof Error ? error.message : String(error))
.toLowerCase()
const status = (error as { status?: number })?.status ??
(error as { statusCode?: number })?.statusCode
if (status === 401 || status === 403 ||
msg.includes('api key') || msg.includes('unauthorized')) {
return 'auth'
}
if (status === 429 || msg.includes('rate limit') ||
msg.includes('quota')) {
return 'rate-limit'
}
if (msg.includes('econnrefused') || msg.includes('fetch failed') ||
msg.includes('etimedout') || msg.includes('socket hang up')) {
return 'network'
}
return 'unknown'
}
// In the queue, the classification controls retry behavior:
const shouldRetry =
category !== 'auth' &&
!currentRun.cancelRequested &&
!this.isRunCostExceeded(run) &&
task.attemptCount <= run.retryLimitÈ pattern matching, non scienza. Ma intercetta i casi comuni e previene la modalità di errore più frustrante: guardare l’app che riprova una chiave API sbagliata all’infinito.
Elaborazione batch che non perde il tuo lavoro
Puoi dare 500 foto all’app e andartene. Le elabora con più worker concorrenti (configurabili, default 3), traccia il progresso in SQLite e riporta il costo in tempo reale usando i conteggi di token effettivi dalle risposte API. Non stime. Se imposti un limite di costo di $2.00, l’app smette di analizzare quando lo raggiunge e segna le immagini rimanenti come saltate.
Il sistema a coda è resistente ai crash. Ogni cambio di stato di un task viene scritto nel database prima di qualsiasi altra cosa. Se Electron crasha, se va via la corrente o se chiudi l’app forzatamente, al prossimo avvio vengono rilevate le esecuzioni interrotte e si riprende da dove si era fermato. Non perderai 200 analisi completate perché l’app è crashata sull’immagine 201.
Puoi anche mettere in pausa a metà batch. Utile se ti accorgi di aver scelto il modello sbagliato o vuoi controllare i primi risultati prima di continuare. E se il primo passaggio torna con bassa confidenza su alcune immagini, puoi configurare l’auto-upgrade: l’app riesegue solo quelle immagini con un modello più costoso.
Confronto EXIF affiancato
La vista dettaglio estrae i dati EXIF originali dal file usando exifr (modello fotocamera, data di scatto, dimensioni e qualsiasi GPS esistente) e li mostra accanto ai risultati dell’analisi AI. Questo è utile in due modi. Primo, se la foto aveva già il GPS integrato, puoi vedere se l’AI concorda. Se le coordinate sono molto diverse, è un segnale di allarme. Secondo, il modello fotocamera e la data ti aiutano a verificare la stima temporale dell’AI. Se l’EXIF dice “Canon EOS R5, marzo 2023” e l’AI dice “stimato 2015-2018”, qualcosa non torna.
I compromessi che abbiamo fatto
Il più grande: BYOK (bring your own API key). Gli utenti devono andare su Google AI Studio o sulla dashboard di OpenAI, creare una chiave API e incollarla nelle nostre impostazioni. Questo crea attrito. Gli utenti non tecnici non lo faranno.
Ma l’alternativa era gestire un nostro proxy API. Questo significa costruire un backend, configurare la fatturazione, gestire la misurazione dell’utilizzo, occuparsi degli abusi e pagare per i server. Per un progetto secondario di cui non eravamo sicuri che qualcuno avrebbe usato, è tanta infrastruttura. BYOK significa che l’app è completamente autonoma. Distribuiamo un binario, gli utenti lo eseguono, noi non manteniamo nulla.
Abbiamo anche deciso di non usare modelli AI locali. Gemma 4, LLaVA e modelli simili possono fare comprensione base delle immagini. Ma quando li abbiamo testati per l’identificazione della posizione, i risultati erano vaghi. “Sembra una spiaggia” non aiuta quando hai bisogno di “Waikiki Beach, Honolulu, Hawaii.” I modelli cloud sono genuinamente migliori in questo perché hanno visto più internet. I requisiti hardware per eseguire un modello di visione decente in locale escluderebbero la maggior parte delle persone che vorrebbero questa app.
Il terzo compromesso è stato supportare tre provider AI dal primo giorno invece di uno solo. Questo ha triplicato il lavoro di integrazione API. Onestamente, il 90% degli utenti userà semplicemente Gemini perché è il più economico. Ma avere opzioni conta se hai già una chiave OpenAI e non vuoi registrarti a un altro servizio.
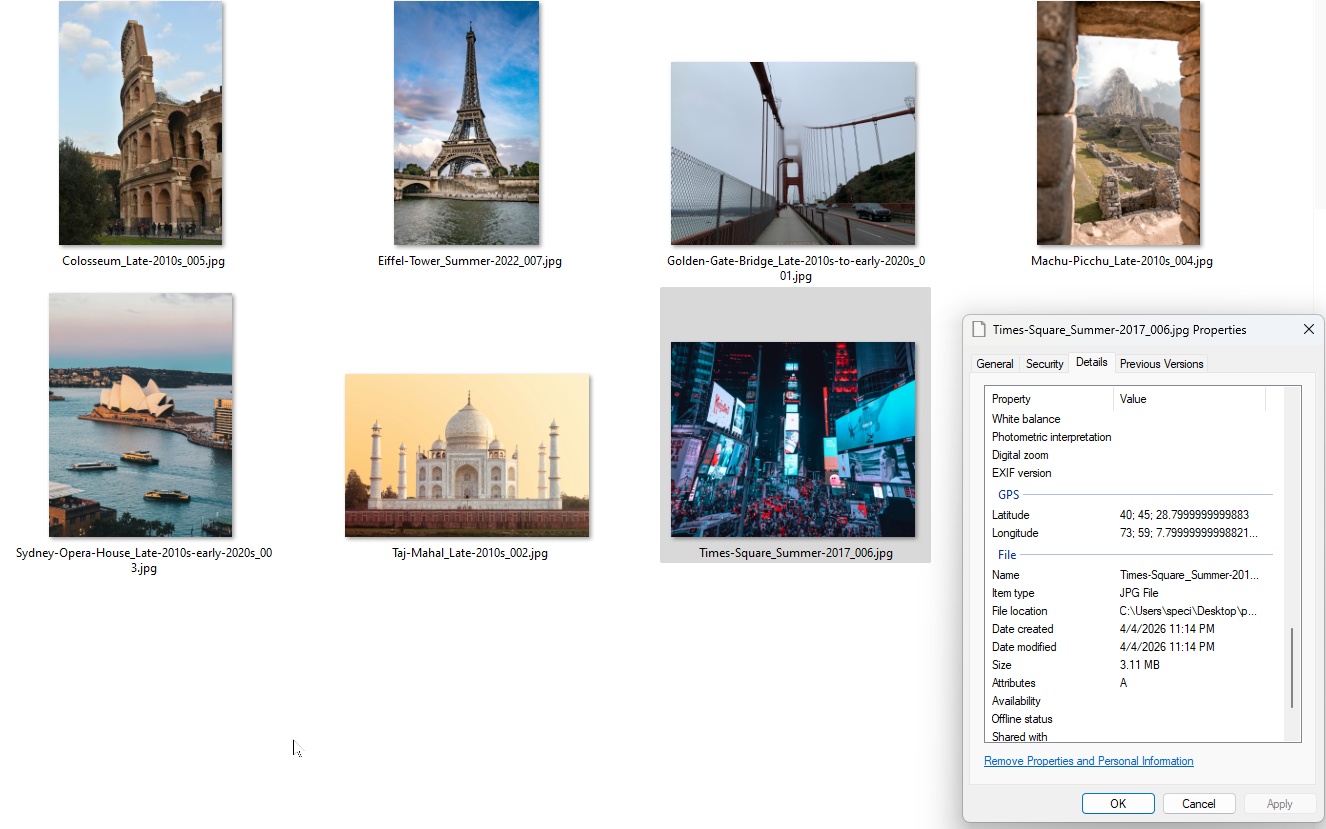
Ed ecco l’output. File rinominati con coordinate GPS integrate nei dati EXIF. Puoi verificarlo nelle proprietà del file di Windows.
Cosa faremmo diversamente
Avremmo distribuito solo con Gemini e aggiunto altri provider in base alla domanda. Tre integrazioni significano tre volte il lavoro, tre volte i casi limite, tre volte i test.
Avremmo anche speso meno tempo a discutere sul prezzo. Abbiamo dibattuto tra gratuito, a pagamento, freemium e open source per troppo tempo. Quel tempo sarebbe stato meglio speso sul prodotto. Alla fine abbiamo scelto open source. Ci sono voluti circa 30 secondi per prendere quella decisione una volta che abbiamo smesso di pensarci troppo.
Sul lato tecnico, avremmo riflettuto di più sullo schema del database fin dall’inizio. Abbiamo aggiunto colonne e migrazioni diverse volte quando arrivavano nuove funzionalità (come il campo state per le posizioni, che inizialmente non avevamo). Partire con uno schema un po’ più flessibile ci avrebbe risparmiato qualche giro di ALTER TABLE.