Hicimos una app que descubre dónde se tomaron tus fotos viejas
Creamos una app de escritorio que envía tus fotos a modelos de IA con visión, recibe datos de ubicación y escribe coordenadas GPS directamente en los archivos.
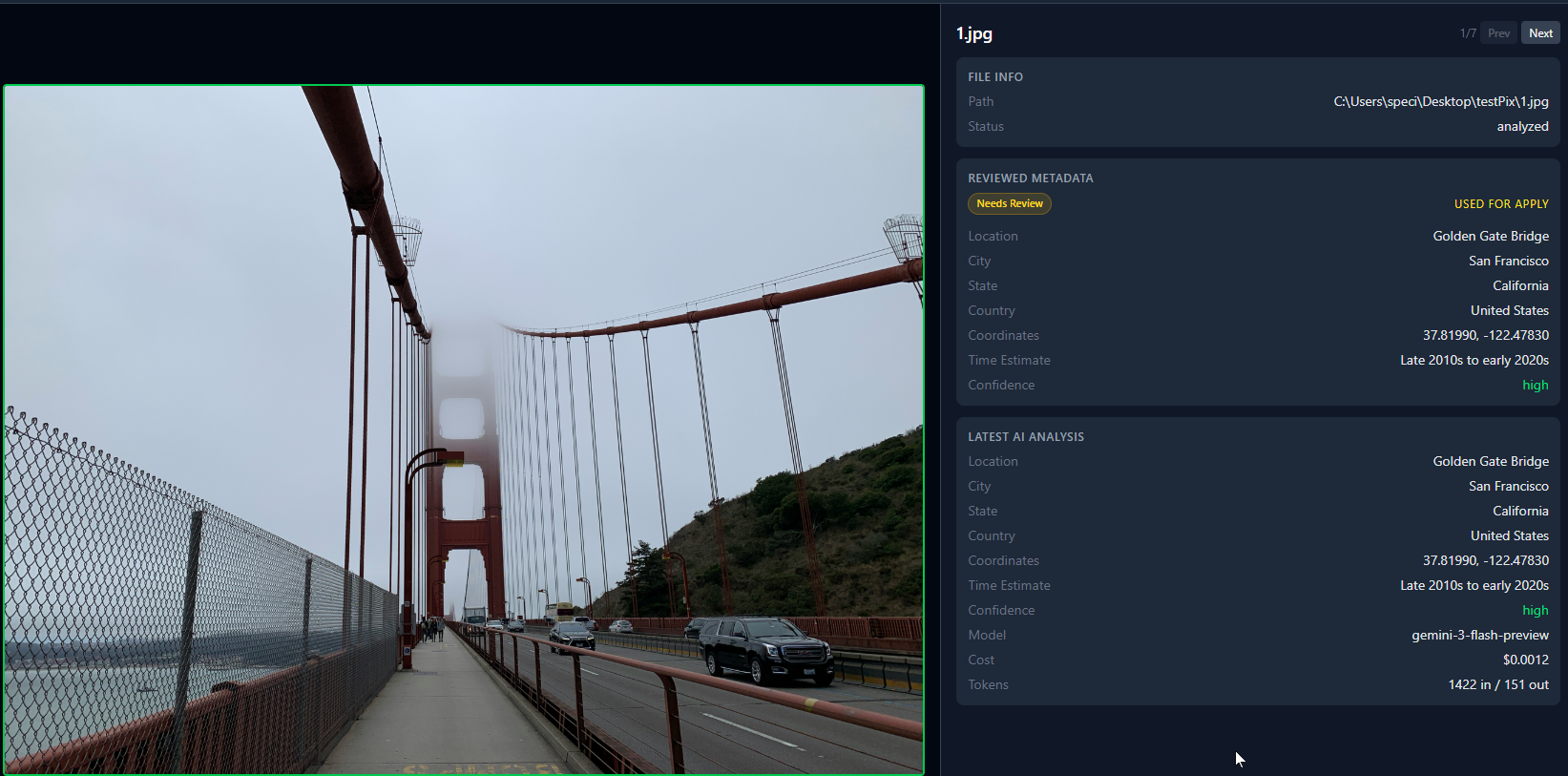
Todos tenemos esa carpeta. Cientos de fotos de viajes viejos, backups del teléfono, descargas aleatorias. Todas se llaman IMG_4523.jpg o DSC_0091.CR2. Sin datos GPS, sin ubicación, nada útil en los metadatos. Medio te acordás de que una foto era de Praga, pero ¿cuál? Ni idea.
Google Photos intenta resolver esto, pero tenés que subir todo a los servidores de Google. Apple Photos hace algo parecido si estás en su ecosistema. Los dos mantienen los datos encerrados en sus plataformas. Nosotros queríamos algo diferente: una app que mire tus fotos, descubra dónde fueron tomadas y escriba esa información de vuelta en los archivos. Cuando terminás, las coordenadas GPS están en los datos EXIF, los archivos tienen nombres útiles y no necesitás ninguna app en particular para leerlos.
Quién usa esto en la vida real
Personas sentadas sobre años de fotos sin organizar que siguen diciendo “algún día las ordeno.” Fotógrafos que disparan en RAW y no tienen GPS en el cuerpo de su cámara. Agentes inmobiliarios con fotos de propiedades que necesitan datos de ubicación. Vendedores de eBay que fotografían productos en el lugar y quieren el GPS grabado en el archivo. Cualquiera que haya abierto una carpeta de fotos y pensado “¿dónde era esto?”
También personas que no quieren subir toda su biblioteca de fotos a un servicio en la nube solo para tener etiquetas de ubicación. Las fotos se envían a un proveedor de IA para análisis (Google, OpenAI o Anthropic), pero no se guardan en ningún lado. Tus archivos se quedan en tu máquina. Los resultados se quedan en una base de datos local.
El stack técnico
La app es Electron con React y TypeScript en el frontend, estilizada con Tailwind CSS v4. Los datos viven en una base de datos local SQLite a través de better-sqlite3. Usamos exiftool-vendored para escribir GPS y otros metadatos en archivos de imagen, y exifr para leer los datos EXIF que ya existan. Las llamadas a IA van por los SDKs oficiales de Google Gemini, OpenAI y Anthropic. El sistema de build es electron-vite para desarrollo y electron-builder para empaquetar instaladores.
Nada exótico. Elegimos herramientas aburridas y bien mantenidas a propósito. Electron recibe críticas por el uso de memoria, pero para una herramienta de escritorio que la gente ejecuta de vez en cuando, funciona bien. Nos permitió publicar para Windows, macOS y Linux desde un solo codebase sin código específico de plataforma.
La parte más difícil: parsear coordenadas GPS
Ni se acerca a cualquier otra cosa.
El problema es este: le preguntás a tres modelos de IA diferentes “¿dónde se tomó esta foto?” y recibís tres formatos de respuesta completamente distintos. Gemini te puede dar {lat: 33.49, lng: -111.93}. OpenAI puede anidarlo bajo {gps_coordinates: {latitude: "33.49 N"}}. Algunos modelos devuelven un string separado por comas como "33.49, -111.93". Otros usan formato DMS como "33°29'N". Algunos meten todo en un array sin razón.
Terminamos escribiendo un normalizador que primero prueba campos directos (lat, latitude, lat_degrees), después busca objetos anidados bajo cuatro nombres de clave diferentes, después intenta parsear strings separados por comas, y después maneja notación DMS. Son unas 50 líneas de código defensivo que existen solo porque los modelos de IA no se ponen de acuerdo en un formato de respuesta. Incluso cuando les decís exactamente lo que querés.
El mejor bug fue el problema del cero falsy. Teníamos Number(val) || null para convertir valores. Funciona genial, excepto cuando la latitud es 0 (que es el ecuador). Number(0) es 0, que es falsy en JavaScript, entonces 0 || null te da null. Estábamos descartando silenciosamente todas las coordenadas GPS del ecuador. Nos tomó más tiempo encontrarlo de lo que nos gustaría admitir.
// Before (broken):
const lat = Number(val) || null // 0 becomes null
// After:
function toNum(v: unknown): number | null {
const n = Number(v)
return isNaN(n) ? null : n
}No lo detectamos por un buen rato porque ninguna de nuestras fotos de prueba era del ecuador. Lo encontramos cuando agregamos un caso de prueba para valores extremos y 0 volvió como null.
Así se ven 7 fotos analizadas en la vista de grilla. Los puntos verdes significan que la IA identificó la ubicación. Los puntos rojos significan baja confianza.
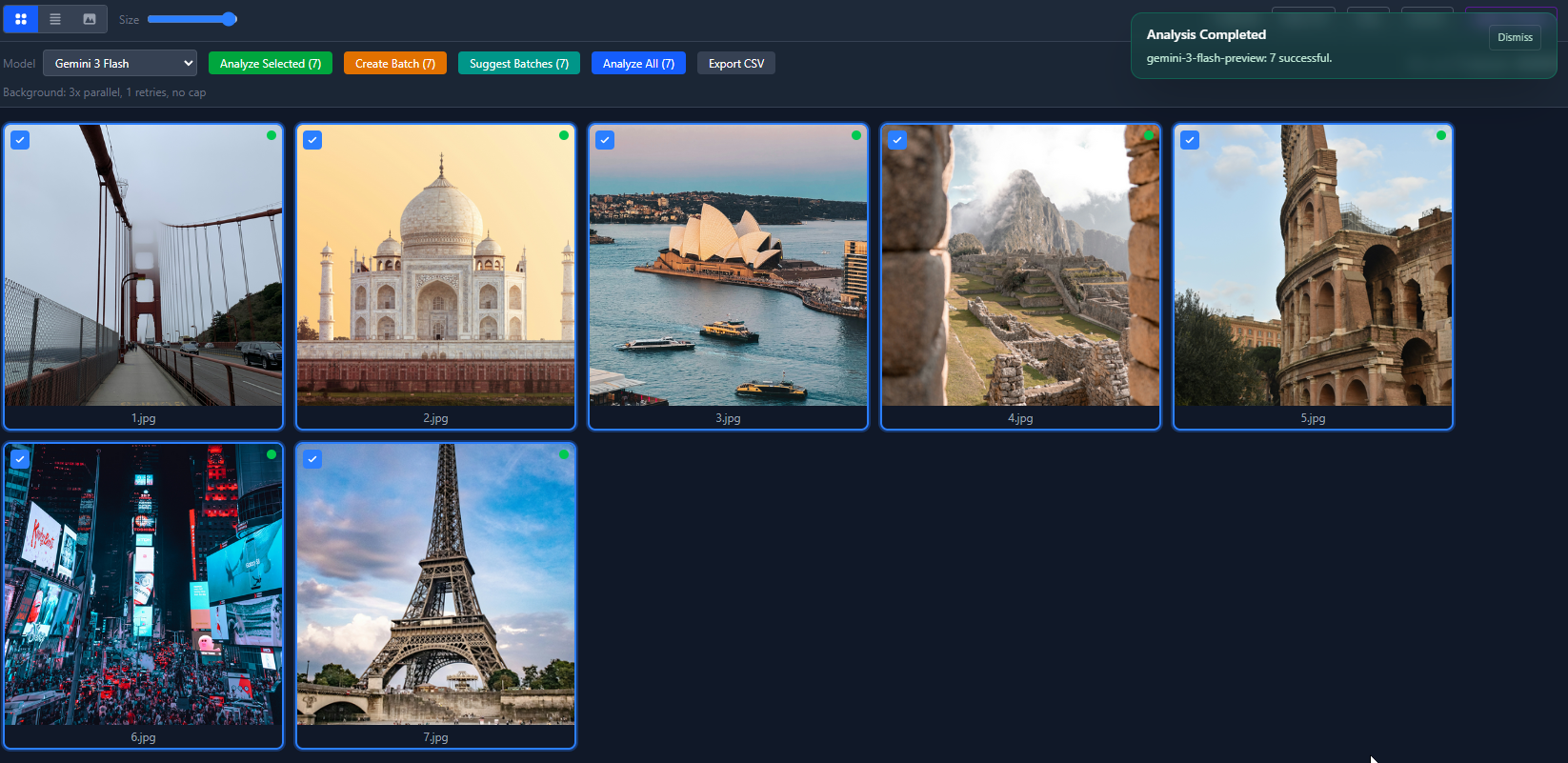
Cómo fluyen los datos
La arquitectura es directa:
- El usuario abre una carpeta. La escaneamos buscando archivos de imagen y creamos un “batch” en SQLite, con una fila por imagen.
- El usuario hace clic en Analyze. Para cada imagen, leemos el archivo, lo codificamos en base64 y lo enviamos al proveedor de IA que hayan elegido. El prompt pide ubicación, ciudad, estado, país, coordenadas GPS, estimación de fecha y nivel de confianza.
- La respuesta de la IA vuelve como JSON (generalmente). La pasamos por nuestro normalizador para manejar todas las variaciones de formato, la validamos contra un esquema Zod y guardamos el resultado en la base de datos. Si el modelo devuelve basura, Zod lo atrapa y la tarea se marca como fallida.
- El usuario revisa los resultados. Puede aprobar, rechazar o editar cada uno. La app muestra los datos EXIF originales al lado de los resultados de la IA para que pueda comparar.
- El usuario hace clic en Apply Changes. Copiamos cada archivo original a una carpeta de salida, usamos exiftool-vendored para escribir las coordenadas GPS en la copia y la renombramos según una plantilla. Los originales nunca se modifican.
El análisis corre a través de un sistema de cola que maneja concurrencia (múltiples imágenes analizadas al mismo tiempo), reintentos en caso de fallo, pausa/reanudación y topes de costo. Todo se rastrea en SQLite. Si la app se cuelga a mitad de un batch, retoma donde quedó.
El modelo de procesos de Electron agrega algo de complejidad. Las llamadas a IA y el I/O de archivos ocurren en el proceso principal. La UI corre en el proceso del renderer. La comunicación entre ellos va por handlers IPC. Tenemos unos 40 endpoints IPC. Son bastantes, pero cada uno hace una sola cosa.
Qué puede hacer en la práctica
Análisis de IA con múltiples proveedores
La app funciona con más de 16 modelos de Google Gemini, OpenAI y Anthropic. Cada proveedor tiene su propia integración por SDK con soporte de salida estructurada (Gemini usa responseSchema, OpenAI usa zodResponseFormat, Anthropic usa output_format). Cuando llega una respuesta, pasa por un normalizador que mapea los nombres de campo que haya usado el modelo (location_name, locationName, specific_location, place) a nuestro formato estándar. El resto de la app nunca sabe qué modelo produjo el resultado.
Esta es la vista de lista después de pasar las 7 fotos por Gemini 3 Flash. Todas volvieron con alta confianza. El costo total fue menos de un centavo.
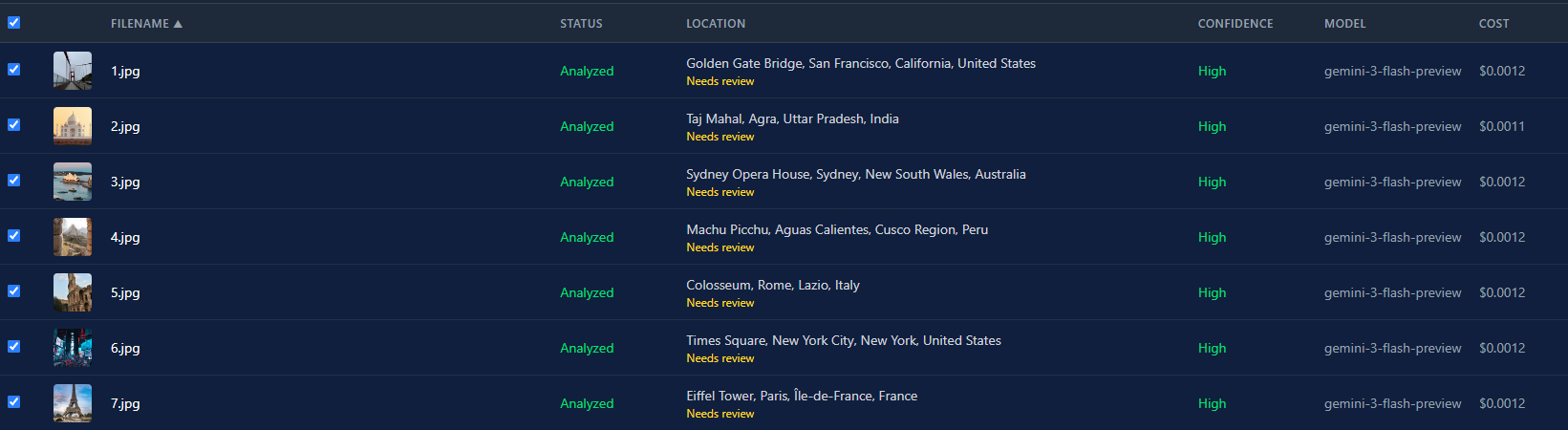
La diferencia de costo entre modelos es enorme. Gemini 3 Flash cuesta alrededor de $0.0004 por imagen. GPT-5 anda por los $0.02. Eso es una diferencia de 50x. Para un batch de 500 fotos, son $0.20 vs. $10. El selector de modelo no es solo una preferencia. Es una decisión real de presupuesto.
Escritura de GPS para casi todos los formatos de imagen
Empezamos con piexifjs para escribir datos EXIF, pero solo maneja JPEG. Eso estaba bien hasta que probamos con bibliotecas de fotos reales. La gente tiene PNGs de capturas de pantalla, HEICs de iPhones, TIFFs de scanners y archivos RAW de cámaras. Así que cambiamos a exiftool-vendored, que envuelve el ExifTool de Phil Harvey. Escribe GPS en JPEG, PNG, TIFF, WebP, HEIC, HEIF, AVIF y un montón de formatos RAW (DNG, CR2, CR3, NEF, ARW, ORF, RW2).
La app siempre escribe en una copia, nunca en el original. Crea una carpeta de salida, copia cada archivo ahí y después escribe los datos GPS en la copia. Si también tenés el renombrado activado, la copia recibe el nombre nuevo. Un archivo de salida por imagen con todo aplicado.
Clasificación de errores que te ahorra tiempo
Cuando una llamada a la API falla, miramos el error y lo clasificamos en una de cuatro categorías: auth (API key mala o expirada), rate-limit (demasiadas peticiones), network (conexión fallida, timeout, problemas de DNS) o unknown. Esto importa porque los errores de auth nunca deberían reintentarse. Si tu API key está mal, reintentar 3 veces solo desperdicia 30 segundos. Los errores de rate-limit y network sí se reintentan porque generalmente son temporales.
export function classifyApiError(error: unknown): ErrorCategory {
const msg = (error instanceof Error ? error.message : String(error))
.toLowerCase()
const status = (error as { status?: number })?.status ??
(error as { statusCode?: number })?.statusCode
if (status === 401 || status === 403 ||
msg.includes('api key') || msg.includes('unauthorized')) {
return 'auth'
}
if (status === 429 || msg.includes('rate limit') ||
msg.includes('quota')) {
return 'rate-limit'
}
if (msg.includes('econnrefused') || msg.includes('fetch failed') ||
msg.includes('etimedout') || msg.includes('socket hang up')) {
return 'network'
}
return 'unknown'
}
// In the queue, the classification controls retry behavior:
const shouldRetry =
category !== 'auth' &&
!currentRun.cancelRequested &&
!this.isRunCostExceeded(run) &&
task.attemptCount <= run.retryLimitEs pattern matching, no ciencia. Pero atrapa los casos comunes y previene el modo de fallo más frustrante: ver cómo la app reintenta una API key mala una y otra vez.
Procesamiento por lotes que no pierde tu trabajo
Podés tirarle 500 fotos a la app e irte. Las procesa con múltiples workers concurrentes (configurable, por defecto 3), rastrea el progreso en SQLite y reporta costo en tiempo real usando conteos reales de tokens de las respuestas de la API. No estimaciones. Si ponés un tope de costo de $2.00, la app deja de analizar cuando llega a ese límite y marca las imágenes restantes como omitidas.
El sistema de cola es resistente a caídas. Cada cambio de estado de tarea va a la base de datos antes de que pase cualquier otra cosa. Si Electron se cuelga, se corta la luz o forzás el cierre de la app, el próximo inicio detecta ejecuciones interrumpidas y retoma donde se detuvo. No vas a perder 200 análisis completados porque la app se colgó en la imagen 201.
También podés pausar a mitad de un batch. Es útil si te das cuenta de que elegiste el modelo equivocado o necesitás revisar los primeros resultados antes de continuar. Y si la primera pasada vuelve con baja confianza en algunas imágenes, podés configurar auto-upgrade: la app vuelve a procesar solo esas imágenes con un modelo más caro.
Comparación EXIF lado a lado
La vista de detalle extrae los datos EXIF originales del archivo usando exifr (modelo de cámara, fecha de captura, dimensiones y cualquier GPS existente) y los muestra al lado de los resultados del análisis de IA. Esto es útil de dos maneras. Primero, si la foto ya tenía GPS, podés ver si la IA coincide. Si las coordenadas están muy lejos, eso es una señal de alerta. Segundo, el modelo de cámara y la fecha te ayudan a verificar la estimación temporal de la IA. Si el EXIF dice “Canon EOS R5, marzo 2023” y la IA dice “estimado 2015-2018,” algo anda mal.
Concesiones que hicimos
La grande: BYOK (bring your own API key). Los usuarios tienen que ir a Google AI Studio o al dashboard de OpenAI, crear una API key y pegarla en nuestra configuración. Eso es fricción real. Los usuarios no técnicos no lo van a hacer.
Pero la alternativa era montar nuestro propio proxy de API. Eso significa construir un backend, configurar facturación, manejar medición de uso, lidiar con abuso y pagar servidores. Para un proyecto secundario del que no estábamos seguros si alguien lo usaría, eso es mucha infraestructura. BYOK significa que la app es completamente independiente. Publicamos un binario, los usuarios lo ejecutan, nosotros no mantenemos nada.
También decidimos no usar modelos de IA locales. Gemma 4, LLaVA y modelos similares pueden hacer análisis básico de imágenes. Pero cuando los probamos para identificar ubicaciones, los resultados eran vagos. “Esto parece una playa” no ayuda cuando necesitás “Playa Waikiki, Honolulu, Hawaii.” Los modelos en la nube son genuinamente mejores en esto porque han visto más del internet. Los requisitos de hardware para correr un modelo de visión decente localmente excluirían a la mayoría de las personas que realmente querrían esta app.
La tercera concesión fue soportar tres proveedores de IA desde el día uno en vez de solo uno. Eso triplicó el trabajo de integración con APIs. Honestamente, el 90% de los usuarios simplemente van a usar Gemini porque es el más barato. Pero tener opciones importa si ya tenés una key de OpenAI y no querés registrarte en otro servicio.
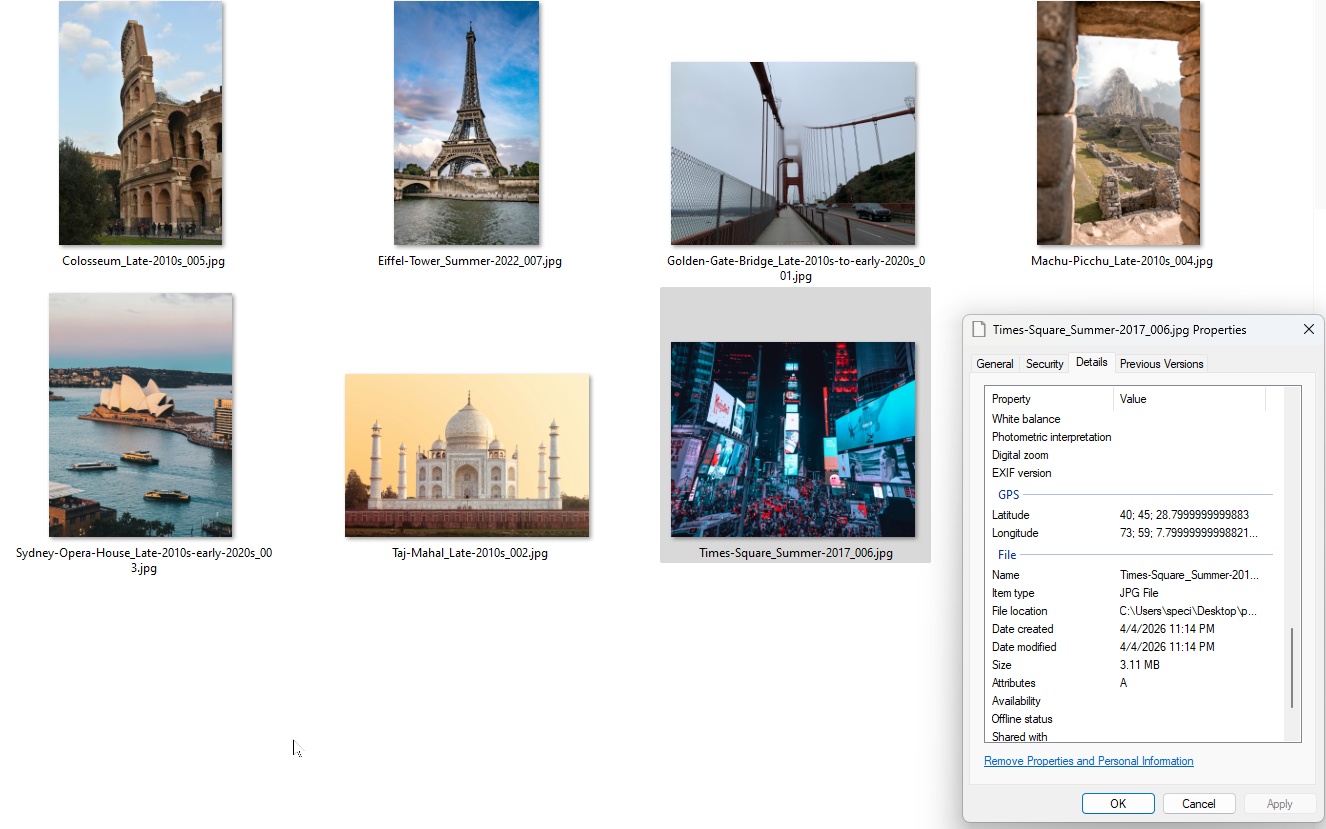
Y acá está la salida. Archivos renombrados con coordenadas GPS grabadas en los datos EXIF. Podés verificarlo en las propiedades de archivo de Windows.
Qué haríamos diferente
Habríamos publicado solo con Gemini y agregado otros proveedores según la demanda. Tres integraciones fue tres veces el trabajo, tres veces los casos extremos, tres veces las pruebas.
También habríamos dedicado menos tiempo yendo y viniendo con el pricing. Debatimos gratis vs. pago vs. freemium vs. open source por demasiado tiempo. Ese tiempo habría sido mejor invertido en el producto real. Al final fuimos open source. Tomó unos 30 segundos tomar esa decisión una vez que dejamos de darle tantas vueltas.
En el lado técnico, habríamos pensado más en el esquema de la base de datos desde el inicio. Agregamos columnas y migraciones varias veces a medida que llegaron nuevas funcionalidades (como el campo de estado para ubicaciones, que no teníamos al principio). Empezar con un esquema un poco más flexible nos habría ahorrado varias rondas de ALTER TABLE.