Wir haben ein Tool gebaut, das herausfindet, wo deine alten Fotos aufgenommen wurden
Wir haben eine Desktop-App gebaut, die deine Fotos an KI-Vision-Modelle schickt, Standortdaten zurückbekommt und GPS-Koordinaten direkt in die Dateien schreibt.
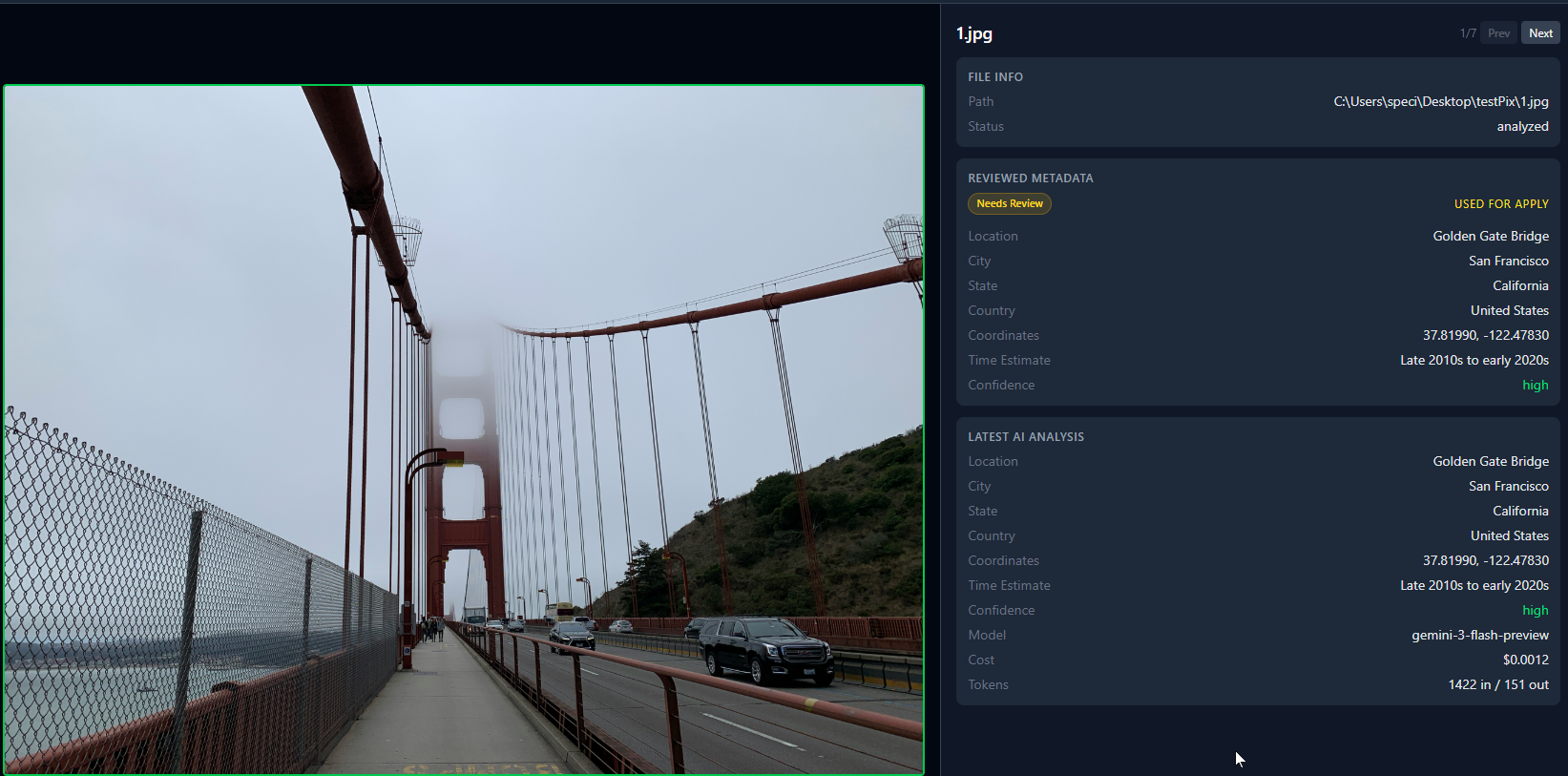
Jeder hat diesen einen Ordner. Hunderte Fotos von alten Reisen, Handy-Backups, zufällige Downloads. Alle heißen IMG_4523.jpg oder DSC_0091.CR2. Keine GPS-Daten, kein Standort, nichts Brauchbares in den Metadaten. Du erinnerst dich vage, dass ein Foto aus Prag war. Aber welches? Keine Ahnung.
Google Photos versucht das zu lösen. Aber du musst alles auf Googles Server hochladen. Apple Photos macht was Ähnliches, wenn du in deren System bist. Beide halten die Daten in ihren Plattformen gefangen. Wir wollten etwas anderes: eine App, die sich deine Fotos anschaut, herausfindet wo sie aufgenommen wurden, und diese Info zurück in die Dateien schreibt. Wenn du fertig bist, stecken die GPS-Koordinaten in den EXIF-Daten. Die Dateien haben brauchbare Namen. Und du brauchst keine bestimmte App, um sie zu lesen.
Wer das wirklich benutzt
Leute, die seit Jahren unsortierte Fotos horten und immer sagen “Ich sortier die irgendwann mal.” Fotografen, die in RAW schießen und kein GPS am Kameragehäuse haben. Immobilienmakler mit Objektfotos, die Standortdaten brauchen. eBay-Verkäufer, die Produkte vor Ort fotografieren und GPS eingebettet haben wollen. Jeder, der schon mal einen Ordner voller Fotos geöffnet hat und dachte “Wo war das nochmal?”
Auch Leute, die nicht ihre gesamte Fotobibliothek in einen Cloud-Dienst hochladen wollen, nur um Standort-Tags zu bekommen. Die Fotos werden zur Analyse an einen KI-Anbieter geschickt (Google, OpenAI oder Anthropic). Aber sie werden nirgendwo gespeichert. Deine Dateien bleiben auf deinem Rechner. Die Ergebnisse bleiben in einer lokalen Datenbank.
Der Tech-Stack
Die App ist Electron mit React und TypeScript im Frontend, gestylt mit Tailwind CSS v4. Daten liegen in einer lokalen SQLite-Datenbank über better-sqlite3. Wir verwenden exiftool-vendored, um GPS und andere Metadaten in Bilddateien zu schreiben. Zum Lesen vorhandener EXIF-Daten kommt exifr zum Einsatz. Die KI-Aufrufe laufen über die offiziellen SDKs für Google Gemini, OpenAI und Anthropic. Build-System ist electron-vite für die Entwicklung und electron-builder für Installer-Pakete.
Nichts Ausgefallenes. Wir haben absichtlich langweilige, gut gepflegte Tools gewählt. Electron wird oft für seinen Speicherverbrauch kritisiert. Aber für ein Desktop-Fototool, das man ab und zu startet, ist es völlig okay. Es hat uns ermöglicht, für Windows, macOS und Linux aus einer Codebase heraus zu liefern. Ohne plattformspezifischen Code.
Der schwierigste Teil: GPS-Koordinaten parsen
Nichts anderes kommt auch nur annähernd ran.
Das Problem: Du fragst drei verschiedene KI-Modelle “Wo wurde dieses Foto aufgenommen?” und bekommst drei komplett unterschiedliche Antwort-Formate. Gemini gibt dir vielleicht {lat: 33.49, lng: -111.93}. OpenAI verschachtelt es unter {gps_coordinates: {latitude: "33.49 N"}}. Manche Modelle geben einen kommaseparierten String zurück wie "33.49, -111.93". Andere verwenden DMS-Format wie "33°29'N". Ein paar packen grundlos alles in ein Array.
Wir haben am Ende einen Normalizer geschrieben, der zuerst direkte Felder probiert (lat, latitude, lat_degrees). Dann prüft er verschachtelte Objekte unter vier verschiedenen Schlüsselnamen. Dann versucht er kommaseparierte Strings zu parsen. Dann behandelt er DMS-Notation. Das sind etwa 50 Zeilen defensiver Code, der nur existiert, weil KI-Modelle sich nicht auf ein Antwortformat einigen können. Selbst wenn du ihnen genau sagst, was du willst.
Der beste Bug war das Falsy-Zero-Problem. Wir hatten Number(val) || null zum Konvertieren von Werten. Funktioniert super, außer wenn der Breitengrad 0 ist (das ist der Äquator). Number(0) ergibt 0, und das ist falsy in JavaScript. Also gibt 0 || null dir null. Wir haben stillschweigend jede GPS-Koordinate am Äquator verworfen. Es hat länger gedauert, das zu finden, als uns lieb ist.
// Before (broken):
const lat = Number(val) || null // 0 becomes null
// After:
function toNum(v: unknown): number | null {
const n = Number(v)
return isNaN(n) ? null : n
}Wir haben es eine Weile nicht bemerkt, weil keines unserer Testfotos vom Äquator war. Entdeckt haben wir es, als wir einen Testfall für Grenzwerte hinzugefügt haben und 0 als null zurückkam.
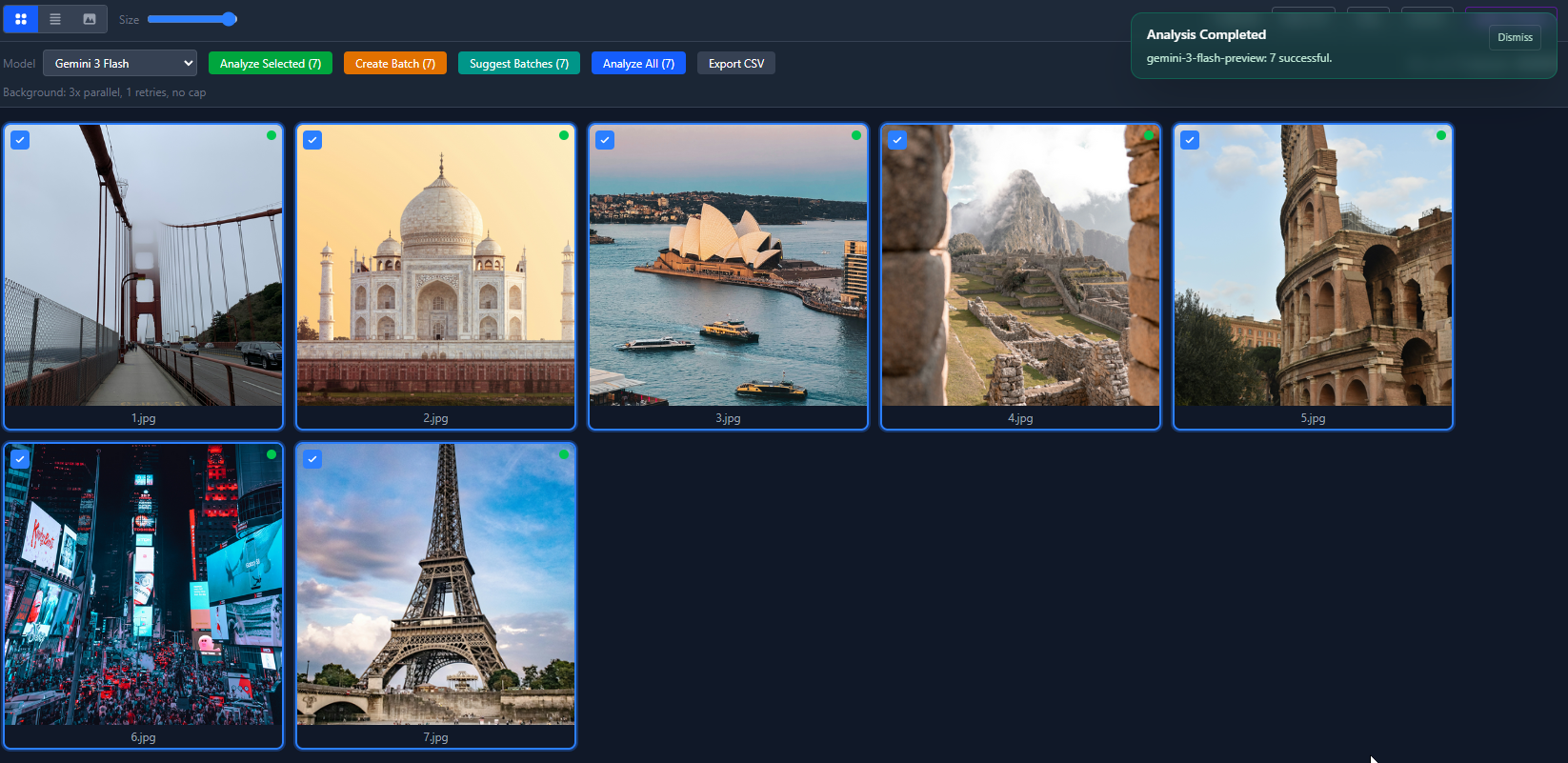
So sehen 7 analysierte Fotos in der Rasteransicht aus. Grüne Punkte bedeuten, dass die KI den Standort erkannt hat. Rote Punkte bedeuten geringe Treffsicherheit.
Wie die Daten fließen
Die Architektur ist unkompliziert:
- Der Benutzer öffnet einen Ordner. Wir scannen ihn nach Bilddateien und erstellen einen “Batch” in SQLite. Pro Bild eine Zeile.
- Der Benutzer klickt auf Analysieren. Für jedes Bild lesen wir die Datei, kodieren sie in Base64 und schicken sie an den gewählten KI-Anbieter. Der Prompt fragt nach Standort, Stadt, Bundesland, Land, GPS-Koordinaten, Zeitschätzung und einem Konfidenz-Level.
- Die KI-Antwort kommt als JSON zurück (meistens). Wir jagen sie durch unseren Normalizer, um alle Format-Varianten abzufangen. Dann validieren wir gegen ein Zod-Schema und speichern das Ergebnis in der Datenbank. Wenn das Modell Müll liefert, fängt Zod das ab und die Aufgabe wird als fehlgeschlagen markiert.
- Der Benutzer überprüft die Ergebnisse. Er kann jedes einzelne genehmigen, ablehnen oder bearbeiten. Die App zeigt die originalen EXIF-Daten neben den KI-Ergebnissen zum Vergleich.
- Der Benutzer klickt auf Änderungen anwenden. Wir kopieren jede Originaldatei in einen Ausgabeordner, schreiben mit exiftool-vendored die GPS-Koordinaten in die Kopie und benennen sie nach einer Vorlage um. Originale werden nie verändert.
Die Analyse läuft über ein Queue-System, das Parallelverarbeitung handhabt (mehrere Bilder gleichzeitig). Dazu Wiederholungsversuche bei Fehlern, Pause/Fortsetzen und Kostenlimits. Alles wird in SQLite festgehalten. Wenn die App mitten im Batch abstürzt, macht sie beim nächsten Start da weiter, wo sie aufgehört hat.
Electrons Prozessmodell macht es etwas komplizierter. Die KI-Aufrufe und Datei-I/O passieren im Main-Prozess. Die UI läuft im Renderer-Prozess. Die Kommunikation dazwischen geht über IPC-Handler. Wir haben etwa 40 IPC-Endpunkte. Das ist viel, aber jeder macht genau eine Sache.
Was die App tatsächlich kann
KI-Analyse mit mehreren Anbietern
Die App funktioniert mit 16+ Modellen von Google Gemini, OpenAI und Anthropic. Jeder Anbieter hat seine eigene SDK-Integration mit Structured-Output-Unterstützung (Gemini verwendet responseSchema, OpenAI verwendet zodResponseFormat, Anthropic verwendet output_format). Wenn eine Antwort zurückkommt, läuft sie durch einen Normalizer. Der bildet alle möglichen Feldnamen (location_name, locationName, specific_location, place) auf unser Standardformat ab. Der Rest der App weiß nie, welches Modell das Ergebnis geliefert hat.
Hier ist die Listenansicht, nachdem alle 7 Fotos durch Gemini 3 Flash gelaufen sind. Alle kamen mit hoher Treffsicherheit zurück. Gesamtkosten unter einem Cent.
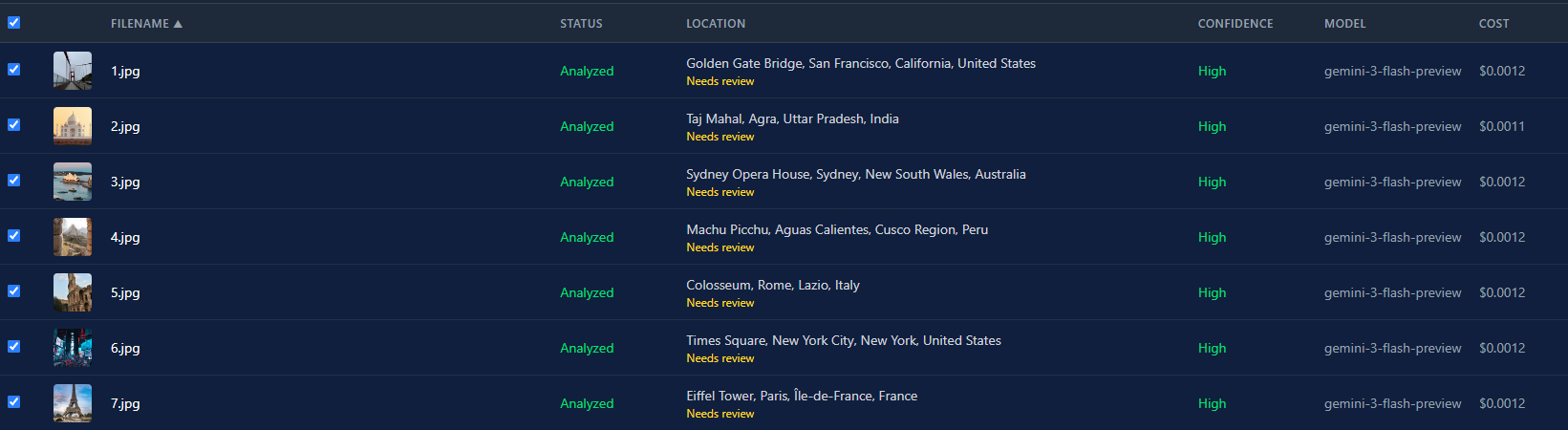
Der Kostenunterschied zwischen Modellen ist enorm. Gemini 3 Flash kostet etwa $0,0004 pro Bild. GPT-5 liegt bei etwa $0,02. Das ist ein 50-facher Unterschied. Bei einem Batch von 500 Fotos sind das $0,20 vs. $10. Die Modellauswahl ist nicht nur eine Geschmacksfrage. Es ist eine echte Budget-Entscheidung.
GPS-Schreibzugriff für so ziemlich jedes Bildformat
Wir haben mit piexifjs angefangen, um EXIF-Daten zu schreiben. Aber das kann nur JPEG. Das war okay, bis wir mit echten Fotobibliotheken getestet haben. Leute haben PNGs von Screenshots, HEICs vom iPhone, TIFFs vom Scanner und RAW-Dateien von Kameras. Also sind wir auf exiftool-vendored umgestiegen, das Phil Harveys ExifTool einhüllt. Es schreibt GPS in JPEG, PNG, TIFF, WebP, HEIC, HEIF, AVIF und eine Reihe von RAW-Formaten (DNG, CR2, CR3, NEF, ARW, ORF, RW2).
Die App schreibt immer in eine Kopie, nie ins Original. Sie erstellt einen Ausgabeordner, kopiert jede Datei dorthin und schreibt dann GPS-Daten in die Kopie. Wenn du auch Umbenennung aktiviert hast, bekommt die Kopie den neuen Namen. Eine Ausgabedatei pro Bild, mit allem drin.
Fehlerklassifizierung, die Zeit spart
Wenn ein API-Aufruf fehlschlägt, schauen wir uns den Fehler an und sortieren ihn in eine von vier Kategorien: Auth (falscher oder abgelaufener API-Key), Rate-Limit (zu viele Anfragen), Netzwerk (Verbindung fehlgeschlagen, Timeout, DNS-Probleme) oder Unbekannt. Das ist wichtig, weil Auth-Fehler nie wiederholt werden sollten. Wenn dein API-Key falsch ist, verschwendest du mit 3 Wiederholungen nur 30 Sekunden. Rate-Limit- und Netzwerkfehler werden wiederholt, weil sie meistens vorübergehend sind.
export function classifyApiError(error: unknown): ErrorCategory {
const msg = (error instanceof Error ? error.message : String(error))
.toLowerCase()
const status = (error as { status?: number })?.status ??
(error as { statusCode?: number })?.statusCode
if (status === 401 || status === 403 ||
msg.includes('api key') || msg.includes('unauthorized')) {
return 'auth'
}
if (status === 429 || msg.includes('rate limit') ||
msg.includes('quota')) {
return 'rate-limit'
}
if (msg.includes('econnrefused') || msg.includes('fetch failed') ||
msg.includes('etimedout') || msg.includes('socket hang up')) {
return 'network'
}
return 'unknown'
}
// In the queue, the classification controls retry behavior:
const shouldRetry =
category !== 'auth' &&
!currentRun.cancelRequested &&
!this.isRunCostExceeded(run) &&
task.attemptCount <= run.retryLimitDas ist Pattern-Matching, keine Wissenschaft. Aber es fängt die häufigen Fälle ab und verhindert den frustrierendsten Fehlerfall: Zuzuschauen, wie die App einen falschen API-Key immer wieder probiert.
Batch-Verarbeitung, die deine Arbeit nicht verliert
Du kannst 500 Fotos in die App werfen und weggehen. Sie verarbeitet sie mit mehreren parallelen Workern (einstellbar, Standard ist 3). Der Fortschritt wird in SQLite festgehalten. Die Kosten werden in Echtzeit angezeigt, basierend auf echten Token-Zahlen aus den API-Antworten. Keine Schätzungen. Wenn du ein Kostenlimit von $2,00 setzt, hört die App auf zu analysieren, sobald es erreicht ist. Verbleibende Bilder werden als übersprungen markiert.
Das Queue-System ist absturzsicher. Jede Statusänderung einer Aufgabe wird in die Datenbank geschrieben, bevor irgendetwas anderes passiert. Wenn Electron abstürzt, der Strom ausfällt oder du die App zwangsbeendest: Beim nächsten Start erkennt sie unterbrochene Durchläufe und macht da weiter, wo sie aufgehört hat. Du verlierst nicht 200 fertige Analysen, weil die App bei Bild 201 abgestürzt ist.
Du kannst auch mitten im Batch pausieren. Praktisch, wenn du merkst, dass du das falsche Modell gewählt hast. Oder wenn du frühe Ergebnisse prüfen willst, bevor es weitergeht. Und wenn der erste Durchlauf bei manchen Bildern niedrige Treffsicherheit ergibt, kannst du Auto-Upgrade konfigurieren: Die App analysiert nur diese Bilder nochmal mit einem teureren Modell.
EXIF-Vergleich Seite an Seite
Die Detailansicht liest die originalen EXIF-Daten mit exifr aus der Datei (Kameramodell, Aufnahmedatum, Abmessungen und vorhandene GPS-Daten). Diese werden neben den KI-Analyseergebnissen angezeigt. Das ist auf zwei Arten nützlich. Erstens: Wenn das Foto schon GPS eingebettet hatte, kannst du sehen, ob die KI damit übereinstimmt. Wenn die Koordinaten weit daneben liegen, ist das ein Warnsignal. Zweitens: Kameramodell und Datum helfen dir, die Zeitschätzung der KI zu überprüfen. Wenn die EXIF-Daten sagen “Canon EOS R5, März 2023” und die KI sagt “geschätzt 2015-2018”, stimmt etwas nicht.
Kompromisse, die wir gemacht haben
Der größte: BYOK (Bring Your Own API Key). Benutzer müssen zu Google AI Studio oder OpenAIs Dashboard gehen, einen API-Key erstellen und ihn in unsere Einstellungen einfügen. Das ist echte Hürde. Nicht-technische Benutzer werden das nicht machen.
Aber die Alternative war, einen eigenen API-Proxy zu betreiben. Das bedeutet: ein Backend bauen, Abrechnung einrichten, Nutzungsmessung implementieren, Missbrauch verhindern und Server bezahlen. Für ein Nebenprojekt, von dem wir nicht wussten, ob es jemand benutzt, ist das eine Menge Aufwand. BYOK bedeutet, die App ist komplett eigenständig. Wir liefern eine Binärdatei, Benutzer starten sie, wir müssen nichts betreiben.
Wir haben uns auch gegen lokale KI-Modelle entschieden. Gemma 4, LLaVA und ähnliche Modelle können grundlegende Bilderkennung. Aber als wir sie für Standort-Erkennung getestet haben, waren die Ergebnisse vage. “Das sieht aus wie ein Strand” hilft nicht, wenn du “Waikiki Beach, Honolulu, Hawaii” brauchst. Cloud-Modelle sind hier wirklich besser, weil sie mehr vom Internet gesehen haben. Die Hardware-Anforderungen für ein brauchbares lokales Vision-Modell würden die meisten Leute ausschließen, die diese App tatsächlich wollen.
Der dritte Kompromiss war, drei KI-Anbieter von Anfang an zu unterstützen, statt nur einen. Das hat den Aufwand für die API-Integration verdreifacht. Ehrlich gesagt werden 90% der Benutzer einfach Gemini verwenden, weil es am günstigsten ist. Aber Optionen sind wichtig, wenn du schon einen OpenAI-Key hast und dich nicht bei einem weiteren Dienst anmelden willst.
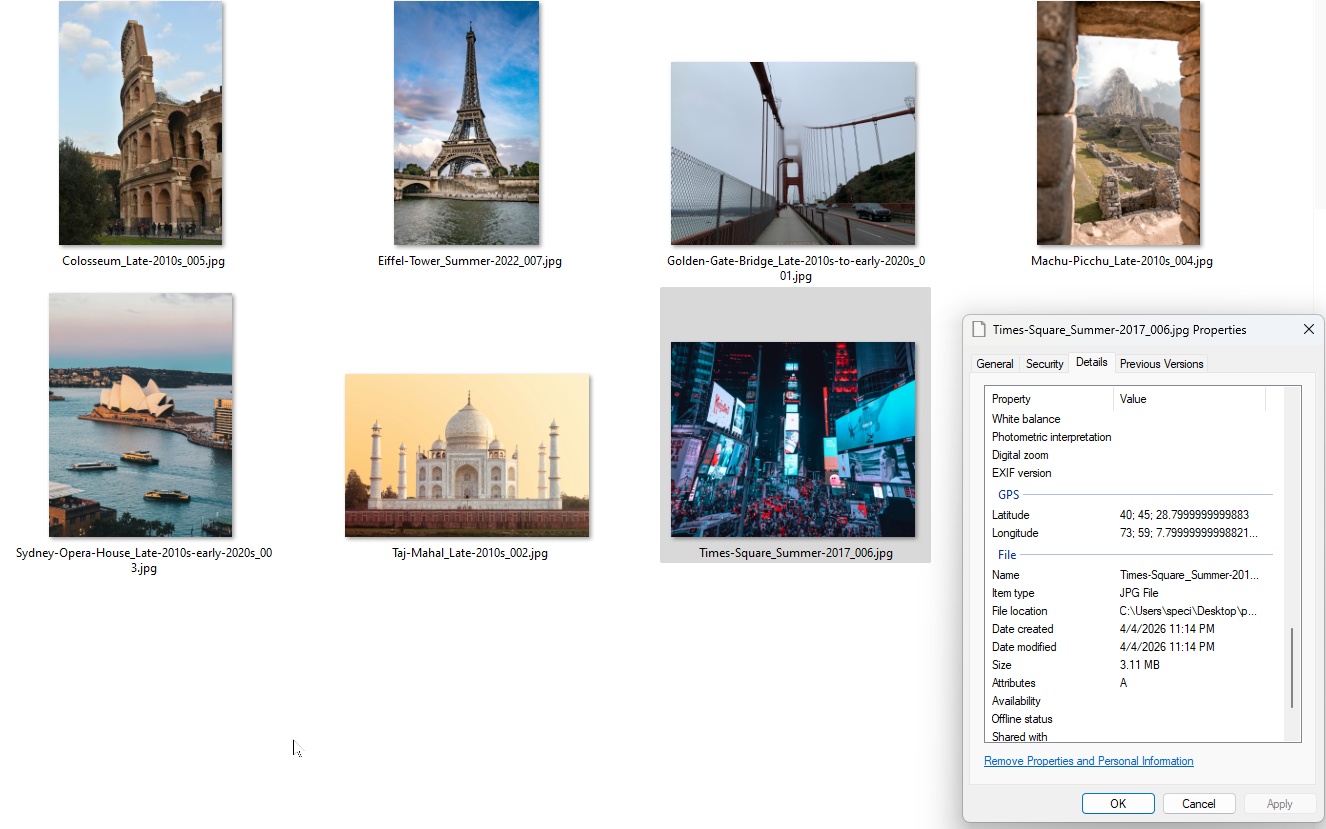
Und hier ist das Ergebnis. Umbenannte Dateien mit GPS-Koordinaten in den EXIF-Daten. Du kannst es in den Windows-Dateieigenschaften überprüfen.
Was wir anders machen würden
Wir würden nur mit Gemini starten und andere Anbieter je nach Nachfrage hinzufügen. Drei Integrationen bedeuteten dreimal so viel Arbeit, dreimal so viele Sonderfälle, dreimal so viel Testen.
Wir würden auch weniger Zeit mit dem Hin und Her zur Preisgestaltung verbringen. Wir haben viel zu lange über kostenlos vs. bezahlt vs. Freemium vs. Open Source debattiert. Diese Zeit wäre besser ins eigentliche Produkt geflossen. Am Ende sind wir Open Source gegangen. Die Entscheidung stand in etwa 30 Sekunden fest, sobald wir aufgehört haben, sie zu zerdenken.
Auf der technischen Seite würden wir von Anfang an mehr über das Datenbankschema nachdenken. Wir haben mehrfach Spalten und Migrationen hinzugefügt, als neue Features dazukamen (zum Beispiel das State-Feld für Standorte, das wir anfangs nicht hatten). Ein etwas flexibleres Schema am Anfang hätte uns ein paar Runden ALTER TABLE erspart.