Zbudowaliśmy narzędzie, które rozpoznaje, gdzie zrobiono stare zdjęcia
Zbudowaliśmy desktopową aplikację, która wysyła twoje zdjęcia do modeli AI, dostaje dane o lokalizacji i zapisuje współrzędne GPS bezpośrednio w plikach.
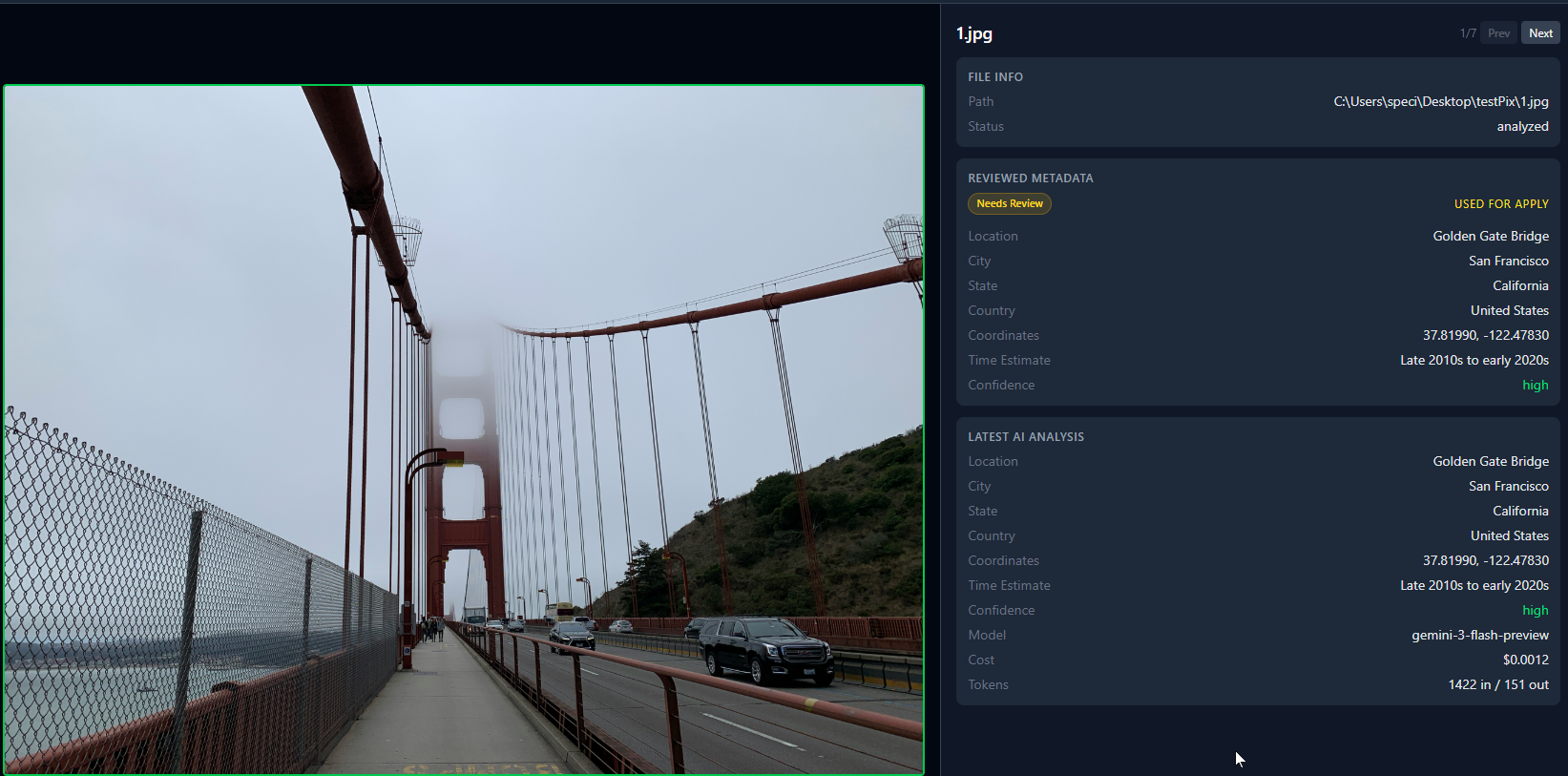
Każdy ma taki folder. Setki zdjęć ze starych wycieczek, kopii zapasowych telefonu, losowych pobrań. Wszystkie nazwane IMG_4523.jpg albo DSC_0091.CR2. Żadnych danych GPS, żadnej lokalizacji, nic przydatnego w metadanych. Mętnie pamiętasz, że jedno zdjęcie było z Pragi. Ale które? Nie masz pojęcia.
Google Photos próbuje to rozwiązać, ale musisz wrzucić wszystko na serwery Google’a. Apple Photos robi coś podobnego, jeśli jesteś w ich ekosystemie. Oba trzymają dane zamknięte na swoich platformach. My chcieliśmy czegoś innego: aplikacji, która przegląda twoje zdjęcia, ustala, gdzie zostały zrobione, i zapisuje te informacje z powrotem do plików. Kiedy skończysz, współrzędne GPS są w danych EXIF, pliki mają sensowne nazwy i nie potrzebujesz żadnej konkretnej aplikacji, żeby je odczytać.
Kto tego faktycznie używa
Ludzie siedzący na latach nieposortowanych zdjęć, którzy wciąż powtarzają “kiedyś to ogarnę”. Fotografowie strzelający w RAW, których korpus aparatu nie ma GPS. Agenci nieruchomości ze zdjęciami nieruchomości, które potrzebują danych lokalizacyjnych. Sprzedawcy na eBay, którzy fotografują produkty na miejscu i chcą mieć GPS wpisany w plik. Każdy, kto kiedykolwiek otworzył folder ze zdjęciami i pomyślał “a gdzie to było?”
Poza tym ludzie, którzy nie chcą wrzucać całej biblioteki zdjęć do chmury tylko po to, żeby dostać tagi lokalizacji. Zdjęcia są wysyłane do dostawcy AI w celu analizy (Google, OpenAI lub Anthropic), ale nie są nigdzie przechowywane. Twoje pliki zostają na twoim komputerze. Wyniki zostają w lokalnej bazie danych.
Stos technologiczny
Aplikacja to Electron z React i TypeScript na frontendzie, stylowany Tailwind CSS v4. Dane żyją w lokalnej bazie SQLite przez better-sqlite3. Używamy exiftool-vendored do zapisywania GPS i innych metadanych do plików graficznych, a exifr do odczytywania istniejących danych EXIF. Wywołania AI idą przez oficjalne SDK dla Google Gemini, OpenAI i Anthropic. System budowania to electron-vite do developmentu i electron-builder do pakowania instalatorów.
Nic egzotycznego. Celowo wybraliśmy nudne, dobrze utrzymane narzędzia. Electron jest krytykowany za zużycie pamięci, ale dla desktopowego narzędzia do zdjęć, które ludzie odpalają od czasu do czasu, jest okej. Pozwolił nam wydać aplikację na Windows, macOS i Linux z jednego codebase’u bez żadnego kodu specyficznego dla platformy.
Najtrudniejsza część: parsowanie współrzędnych GPS
Nawet nie było blisko niczego innego.
Problem jest taki: pytasz trzy różne modele AI “gdzie zrobiono to zdjęcie?” i dostajesz trzy kompletnie różne formaty odpowiedzi. Gemini może dać {lat: 33.49, lng: -111.93}. OpenAI może to zagnieździć pod {gps_coordinates: {latitude: "33.49 N"}}. Niektóre modele zwracają string rozdzielony przecinkami: "33.49, -111.93". Inne używają formatu DMS: "33°29'N". Kilka pakuje wszystko w tablicę bez żadnego powodu.
Napisaliśmy normalizer, który najpierw próbuje bezpośrednich pól (lat, latitude, lat_degrees), potem sprawdza zagnieżdżone obiekty pod czterema różnymi nazwami kluczy, potem próbuje parsować stringi rozdzielone przecinkami, potem obsługuje notację DMS. To około 50 linii defensywnego kodu, który istnieje wyłącznie dlatego, że modele AI nie potrafią się zgodzić co do formatu odpowiedzi. Nawet kiedy im dokładnie powiesz, czego chcesz.
Najlepszy bug to był problem z fałszywym zerem. Mieliśmy Number(val) || null do konwersji wartości. Działa świetnie, oprócz sytuacji, gdy szerokość geograficzna wynosi 0 (czyli równik). Number(0) to 0, co jest falsy w JavaScript, więc 0 || null daje null. Cicho pożeraliśmy każdą współrzędną GPS na równiku. Znalezienie tego zajęło nam więcej czasu, niż chcielibyśmy przyznać.
// Before (broken):
const lat = Number(val) || null // 0 becomes null
// After:
function toNum(v: unknown): number | null {
const n = Number(v)
return isNaN(n) ? null : n
}Przez dłuższy czas tego nie wyłapaliśmy, bo żadne z naszych testowych zdjęć nie było z równika. Znaleźliśmy to, gdy dodaliśmy test case dla wartości brzegowych i 0 wróciło jako null.
Tak wygląda 7 przeanalizowanych zdjęć w widoku siatki. Zielone kropki oznaczają, że AI zidentyfikowało lokalizację. Czerwone kropki oznaczają niską pewność.
Jak przepływają dane
Architektura jest prosta:
- Użytkownik otwiera folder. Skanujemy go w poszukiwaniu plików graficznych i tworzymy “batch” w SQLite, z jednym wierszem na zdjęcie.
- Użytkownik klika Analyze. Dla każdego zdjęcia czytamy plik, kodujemy go w base64 i wysyłamy do wybranego dostawcy AI. Prompt prosi o lokalizację, miasto, stan, kraj, współrzędne GPS, szacunek czasu i poziom pewności.
- Odpowiedź AI wraca jako JSON (zazwyczaj). Przepuszczamy ją przez nasz normalizer, żeby obsłużyć wszystkie warianty formatów, walidujemy ją schematem Zod i zapisujemy wynik w bazie. Jeśli model zwraca śmieci, Zod to łapie i zadanie jest oznaczane jako nieudane.
- Użytkownik przegląda wyniki. Może zatwierdzić, odrzucić lub edytować każdy z nich. Aplikacja pokazuje oryginalne dane EXIF obok wyników AI, żeby można było porównać.
- Użytkownik klika Apply Changes. Kopiujemy każdy oryginalny plik do folderu wyjściowego, używamy exiftool-vendored do zapisania współrzędnych GPS w kopii i zmieniamy nazwę na podstawie szablonu. Oryginały nigdy nie są modyfikowane.
Analiza działa przez system kolejki, który obsługuje współbieżność (wiele zdjęć analizowanych jednocześnie), ponawianie po błędzie, pauzę/wznowienie i limity kosztów. Wszystko jest śledzone w SQLite. Jeśli aplikacja się wysypie w trakcie batcha, wznawia pracę od miejsca, w którym skończyła.
Model procesów Electrona dodaje trochę złożoności. Wywołania AI i operacje na plikach dzieją się w procesie głównym. UI działa w procesie renderera. Komunikacja między nimi idzie przez handlery IPC. Mamy około 40 endpointów IPC. To dużo, ale każdy robi jedną rzecz.
Co faktycznie potrafi
Analiza AI z wieloma dostawcami
Aplikacja działa z 16+ modelami z Google Gemini, OpenAI i Anthropic. Każdy dostawca ma własną integrację SDK ze wsparciem dla strukturyzowanych odpowiedzi (Gemini używa responseSchema, OpenAI używa zodResponseFormat, Anthropic używa output_format). Kiedy odpowiedź wraca, przechodzi przez normalizer, który mapuje nazwy pól użyte przez model (location_name, locationName, specific_location, place) na nasz standardowy format. Reszta aplikacji nigdy nie wie, który model wygenerował wynik.
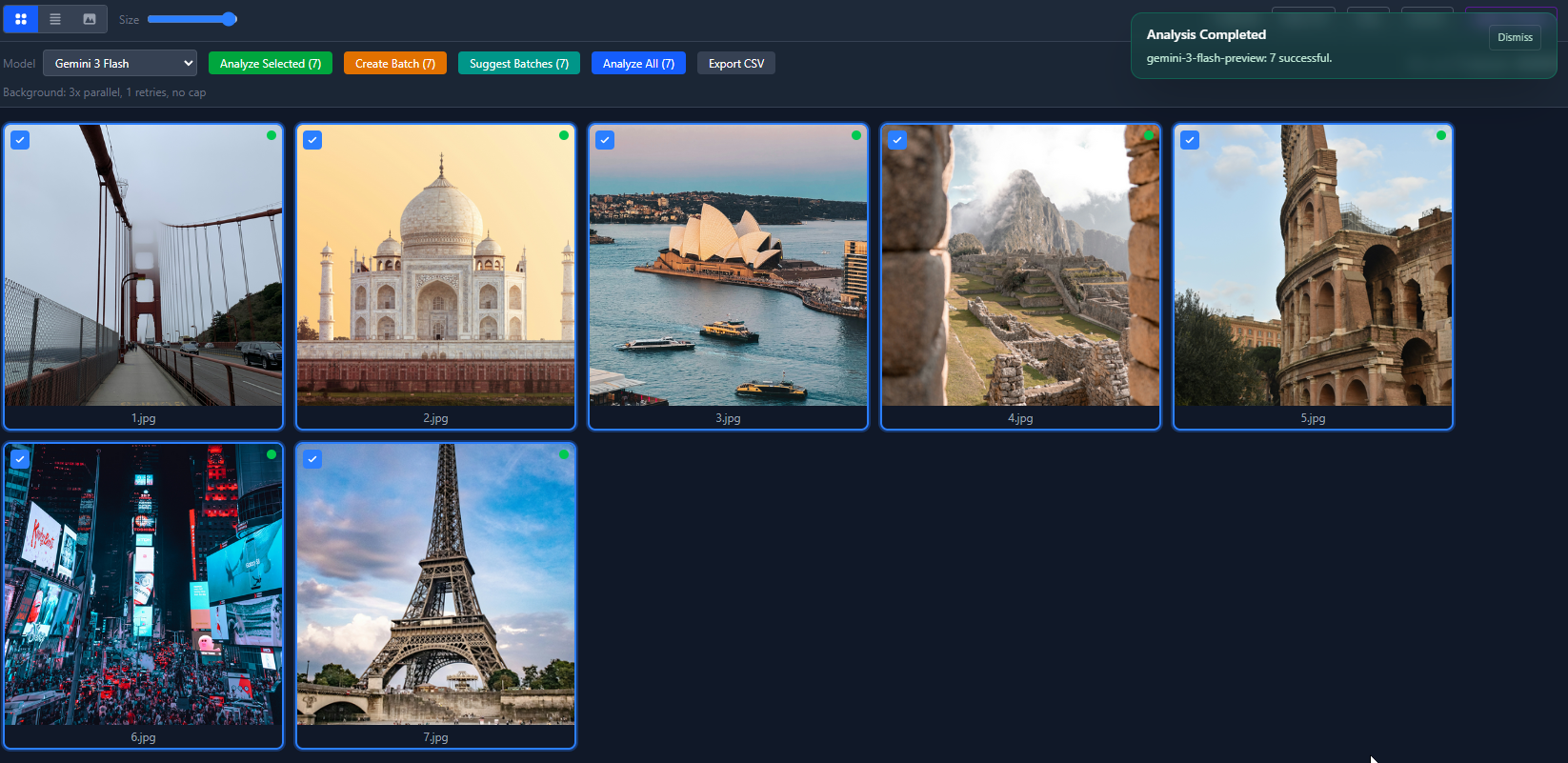
Tak wygląda widok listy po przepuszczeniu wszystkich 7 zdjęć przez Gemini 3 Flash. Każde wróciło z wysoką pewnością. Łączny koszt poniżej centa.
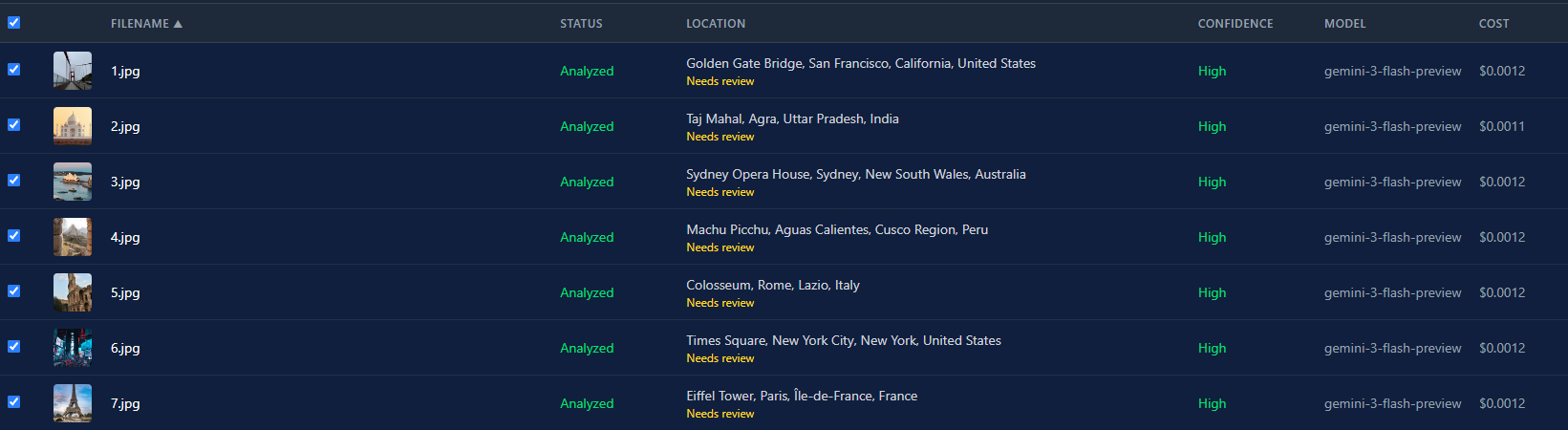
Różnica w kosztach między modelami jest ogromna. Gemini 3 Flash to około $0.0004 za zdjęcie. GPT-5 to około $0.02. To 50-krotna różnica. Dla batcha 500 zdjęć to $0.20 vs. $10. Wybór modelu to nie kwestia preferencji. To realna decyzja budżetowa.
Zapis GPS w praktycznie każdym formacie graficznym
Zaczęliśmy od piexifjs do zapisu danych EXIF, ale obsługuje on tylko JPEG. To było okej, dopóki nie przetestowaliśmy z prawdziwymi bibliotekami zdjęć. Ludzie mają PNG ze screenshotów, HEIC z iPhone’ów, TIFF ze skanerów i pliki RAW z aparatów. Więc przesiedliśmy się na exiftool-vendored, który opakowuje ExifTool Phila Harveya. Zapisuje GPS do JPEG, PNG, TIFF, WebP, HEIC, HEIF, AVIF i kilku formatów RAW (DNG, CR2, CR3, NEF, ARW, ORF, RW2).
Aplikacja zawsze zapisuje do kopii, nigdy do oryginału. Tworzy folder wyjściowy, kopiuje tam każdy plik, a potem zapisuje dane GPS w kopii. Jeśli masz włączoną zmianę nazw, kopia dostaje nową nazwę. Jeden plik wyjściowy na zdjęcie ze wszystkim zaaplikowanym.
Klasyfikacja błędów, która oszczędza czas
Kiedy wywołanie API się nie powiedzie, sprawdzamy błąd i sortujemy go do jednej z czterech kategorii: auth (zły lub wygasły klucz API), rate-limit (za dużo żądań), network (połączenie nie działa, timeout, problemy z DNS) lub unknown. To ważne, bo błędy auth nigdy nie powinny być ponawiane. Jeśli twój klucz API jest zły, ponawianie 3 razy tylko marnuje 30 sekund. Błędy rate-limit i network są ponawiane, bo zazwyczaj są tymczasowe.
export function classifyApiError(error: unknown): ErrorCategory {
const msg = (error instanceof Error ? error.message : String(error))
.toLowerCase()
const status = (error as { status?: number })?.status ??
(error as { statusCode?: number })?.statusCode
if (status === 401 || status === 403 ||
msg.includes('api key') || msg.includes('unauthorized')) {
return 'auth'
}
if (status === 429 || msg.includes('rate limit') ||
msg.includes('quota')) {
return 'rate-limit'
}
if (msg.includes('econnrefused') || msg.includes('fetch failed') ||
msg.includes('etimedout') || msg.includes('socket hang up')) {
return 'network'
}
return 'unknown'
}
// In the queue, the classification controls retry behavior:
const shouldRetry =
category !== 'auth' &&
!currentRun.cancelRequested &&
!this.isRunCostExceeded(run) &&
task.attemptCount <= run.retryLimitTo dopasowywanie wzorców, nie nauka ścisła. Ale łapie typowe przypadki i zapobiega najbardziej frustrującemu trybowi awarii: patrzeniu, jak aplikacja ponawia zły klucz API w kółko.
Przetwarzanie wsadowe, które nie traci twojej pracy
Możesz wrzucić 500 zdjęć do aplikacji i odejść. Przetwarza je z wieloma równoległymi workerami (konfigurowalne, domyślnie 3), śledzi postęp w SQLite i raportuje koszt w czasie rzeczywistym na podstawie faktycznej liczby tokenów z odpowiedzi API. Nie szacunki. Jeśli ustawisz limit kosztów na $2.00, aplikacja przestaje analizować po osiągnięciu tego limitu i oznacza pozostałe zdjęcia jako pominięte.
System kolejki jest odporny na awarie. Każda zmiana stanu zadania trafia do bazy przed czymkolwiek innym. Jeśli Electron się wysypie, prąd padnie, albo wymusisz zamknięcie aplikacji, następne uruchomienie wykrywa przerwane przebiegi i wznawia pracę od miejsca, w którym się zatrzymały. Nie stracisz 200 ukończonych analiz, bo aplikacja się wysypała na zdjęciu 201.
Możesz też wstrzymać przetwarzanie w trakcie batcha. Przydatne, jeśli zorientujesz się, że wybrałeś zły model albo chcesz sprawdzić wczesne wyniki przed kontynuowaniem. A jeśli pierwszy przebieg wraca z niską pewnością dla niektórych zdjęć, możesz skonfigurować auto-upgrade: aplikacja przetwarza ponownie tylko te zdjęcia droższym modelem.
Porównanie EXIF obok siebie
Widok szczegółowy wyciąga oryginalne dane EXIF z pliku za pomocą exifr (model aparatu, data zdjęcia, wymiary i istniejące dane GPS) i pokazuje je obok wyników analizy AI. To przydatne na dwa sposoby. Po pierwsze, jeśli zdjęcie miało już wpisane GPS, widzisz, czy AI się z tym zgadza. Jeśli współrzędne są mocno rozbieżne, to czerwona flaga. Po drugie, model aparatu i data pomagają zweryfikować szacunek czasu AI. Jeśli EXIF mówi “Canon EOS R5, marzec 2023”, a AI mówi “szacunkowo 2015-2018”, coś jest nie tak.
Kompromisy, na które poszliśmy
Największy: BYOK (bring your own API key, czyli przynieś swój własny klucz). Użytkownicy muszą wejść do Google AI Studio albo dashboardu OpenAI, stworzyć klucz API i wkleić go w nasze ustawienia. To realna bariera. Nietechniczni użytkownicy tego nie zrobią.
Ale alternatywą było postawienie własnego proxy API. To oznacza budowanie backendu, ustawianie billingu, pomiar użycia, obsługę nadużyć i płacenie za serwery. Dla pobocznego projektu, co do którego nie byliśmy pewni, czy ktokolwiek go użyje, to dużo infrastruktury. BYOK oznacza, że aplikacja jest w pełni samodzielna. Wydajemy binarke, użytkownicy ją uruchamiają, my nic nie utrzymujemy.
Zdecydowaliśmy się też przeciw lokalnym modelom AI. Gemma 4, LLaVA i podobne modele potrafią robić podstawowe rozpoznawanie obrazów. Ale kiedy testowaliśmy je pod kątem identyfikacji lokalizacji, wyniki były mgliste. “To wygląda jak plaża” nie pomaga, kiedy potrzebujesz “Waikiki Beach, Honolulu, Hawaii.” Modele w chmurze są tu naprawdę lepsze, bo widziały więcej internetu. Wymagania sprzętowe do uruchomienia przyzwoitego modelu wizyjnego lokalnie wykluczyłyby większość ludzi, którzy faktycznie chcieliby tej aplikacji.
Trzeci kompromis to obsługa trzech dostawców AI od pierwszego dnia zamiast jednego. To potroiło pracę nad integracją API. Szczerze mówiąc, 90% użytkowników po prostu użyje Gemini, bo jest najtańsze. Ale opcje mają znaczenie, jeśli masz już klucz OpenAI i nie chcesz rejestrować się do kolejnego serwisu.
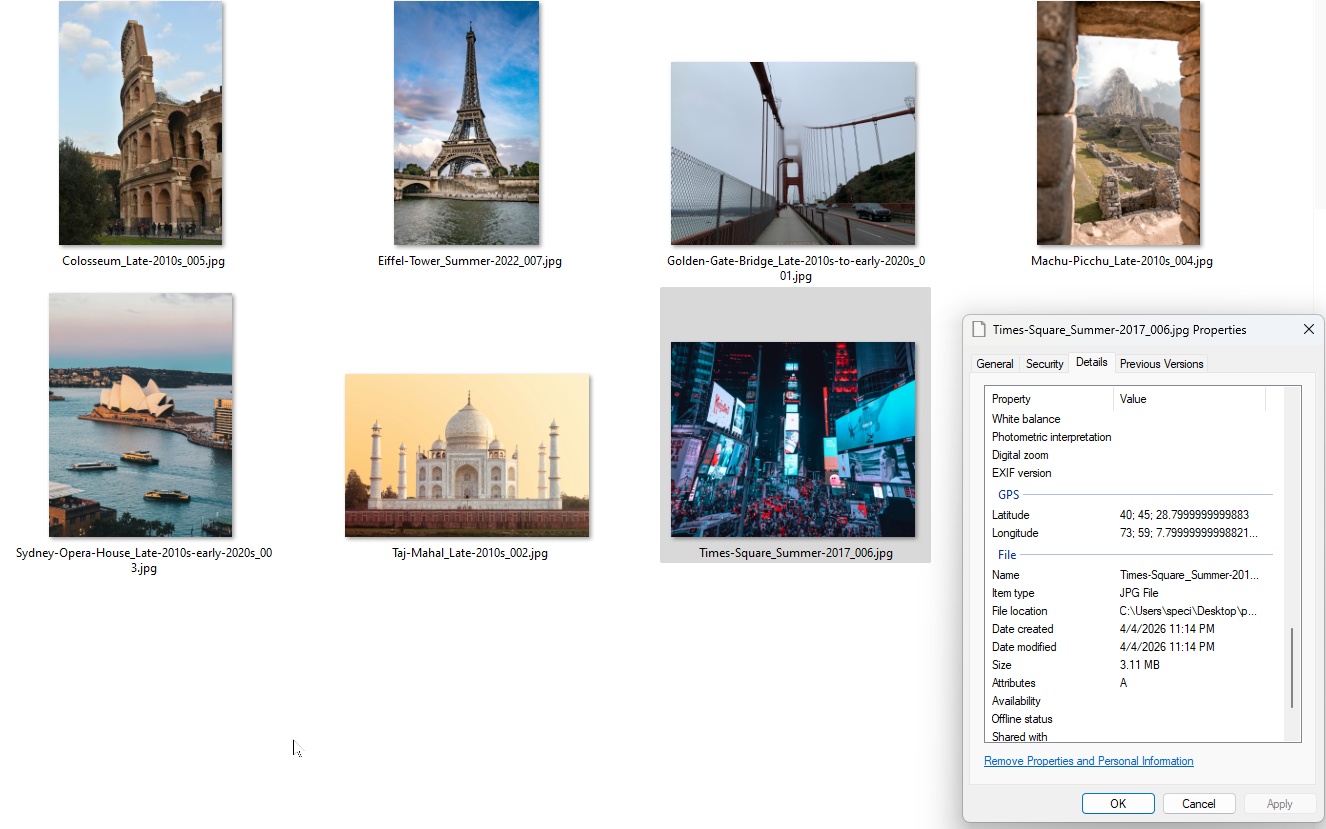
A tu wynik końcowy. Pliki ze zmienionymi nazwami i współrzędnymi GPS zapisanymi w danych EXIF. Możesz to zweryfikować we właściwościach pliku w Windows.
Co zrobilibyśmy inaczej
Wydalibyśmy aplikację tylko z Gemini i dodawali innych dostawców na podstawie zapotrzebowania. Trzy integracje to trzy razy tyle pracy, trzy razy tyle edge case’ów, trzy razy tyle testowania.
Poświęcilibyśmy też mniej czasu na rozkminianie cen. Debatowaliśmy nad darmowe vs. płatne vs. freemium vs. open source zdecydowanie za długo. Ten czas byłby lepiej spędzony na samym produkcie. Ostatecznie poszliśmy w open source. Podjęcie tej decyzji zajęło jakieś 30 sekund, kiedy przestaliśmy to przekombinowywać.
Od strony technicznej zastanowilibyśmy się lepiej nad schematem bazy danych od samego początku. Dodawaliśmy kolumny i migracje kilka razy, kiedy wchodziły nowe funkcjonalności (jak pole state dla lokalizacji, którego początkowo nie mieliśmy). Odrobinę bardziej elastyczny schemat na start zaoszczędziłby kilku rund ALTER TABLE.